
Part 3: Serving an ML Model¶
This part of the MLRun getting-started tutorial walks you through the steps for implementing ML model serving using MLRun serving and Nuclio runtimes. The tutorial walks you through the steps for creating, deploying, and testing a model-serving function (“a serving function” a.k.a. “a model server”).
MLRun serving can produce managed real-time serverless pipelines from various tasks, including MLRun models or standard model files. The pipelines use the Nuclio real-time serverless engine, which can be deployed anywhere. Nuclio is a high-performance open-source “serverless” framework that’s focused on data, I/O, and compute-intensive workloads.
Simple model serving classes can be written in Python or be taken from a set of pre-developed ML/DL classes. The code can handle complex data, feature preparation, and binary data (such as images and video files). The Nuclio serving engine supports the full model-serving life cycle; this includes auto generation of microservices, APIs, load balancing, model logging and monitoring, and configuration management.
MLRun serving supports more advanced real-time data processing and model serving pipelines. For more details and examples, see the MLRun Serving Graphs documentation.
The tutorial consists of the following steps:
Setup and Configuration — load your project
By the end of this tutorial you’ll learn how to
Create model-serving functions.
Deploy models at scale.
Test your deployed models.
Prerequisites¶
The following steps are a continuation of the previous parts of this getting-started tutorial and rely on the generated outputs. Therefore, make sure to first run parts 1—2 of the tutorial.
Step 1: Setup and Configuration¶
Initializing Your MLRun Environment¶
Use the get_or_create_project MLRun method to create a new project or fetch it from the DB/repository if it already exists.
Set the project and user_project parameters to the same values that you used in the call to this method in the Part 1: MLRun Basics tutorial notebook.
# Set the base project name
project_name_base = 'getting-started'
# Initialize the MLRun project object
project = mlrun.get_or_create_project(project_name_base, context="./", user_project=True)
> 2022-02-08 19:57:17,874 [info] loaded project getting-started from MLRun DB
Step 2: Writing A Simple Serving Class¶
The serving class is initialized automatically by the model server. All you need is to implement two mandatory methods:
load— downloads the model files and loads the model into memory. This can be done either synchronously or asynchronously.predict— accepts a request payload and returns prediction (inference) results.
For more detailed information on serving classes, see the MLRun documentation.
The following code demonstrates a minimal scikit-learn (a.k.a. sklearn) serving-class implementation:
# mlrun: start-code
from cloudpickle import load
import numpy as np
from typing import List
import mlrun
class ClassifierModel(mlrun.serving.V2ModelServer):
def load(self):
"""load and initialize the model and/or other elements"""
model_file, extra_data = self.get_model('.pkl')
self.model = load(open(model_file, 'rb'))
def predict(self, body: dict) -> List:
"""Generate model predictions from sample."""
feats = np.asarray(body['inputs'])
result: np.ndarray = self.model.predict(feats)
return result.tolist()
# mlrun: end-code
Step 3: Deploying the Model-Serving Function (Service)¶
To provision (deploy) a function for serving the model (“a serving function”) you need to create an MLRun function of type serving.
You can do this by using the code_to_function MLRun method from a web notebook, or by importing an existing serving function or template from the MLRun functions marketplace.
Converting a Serving Class to a Serving Function¶
The following code converts the ClassifierModel class that you defined in the previous step to a serving function.
The name of the class to be used by the serving function is set in spec.default_class.
serving_fn = mlrun.code_to_function('serving', kind='serving',image='mlrun/mlrun')
serving_fn.spec.default_class = 'ClassifierModel'
Add the model created in previous notebook by the training function
model_file = project.get_artifact_uri('my_model')
serving_fn.add_model('my_model',model_path=model_file)
<mlrun.serving.states.TaskStep at 0x7fec77d70390>
Testing Your Function Locally¶
To test your function locally, create a test server (mock server) and test it with sample data.
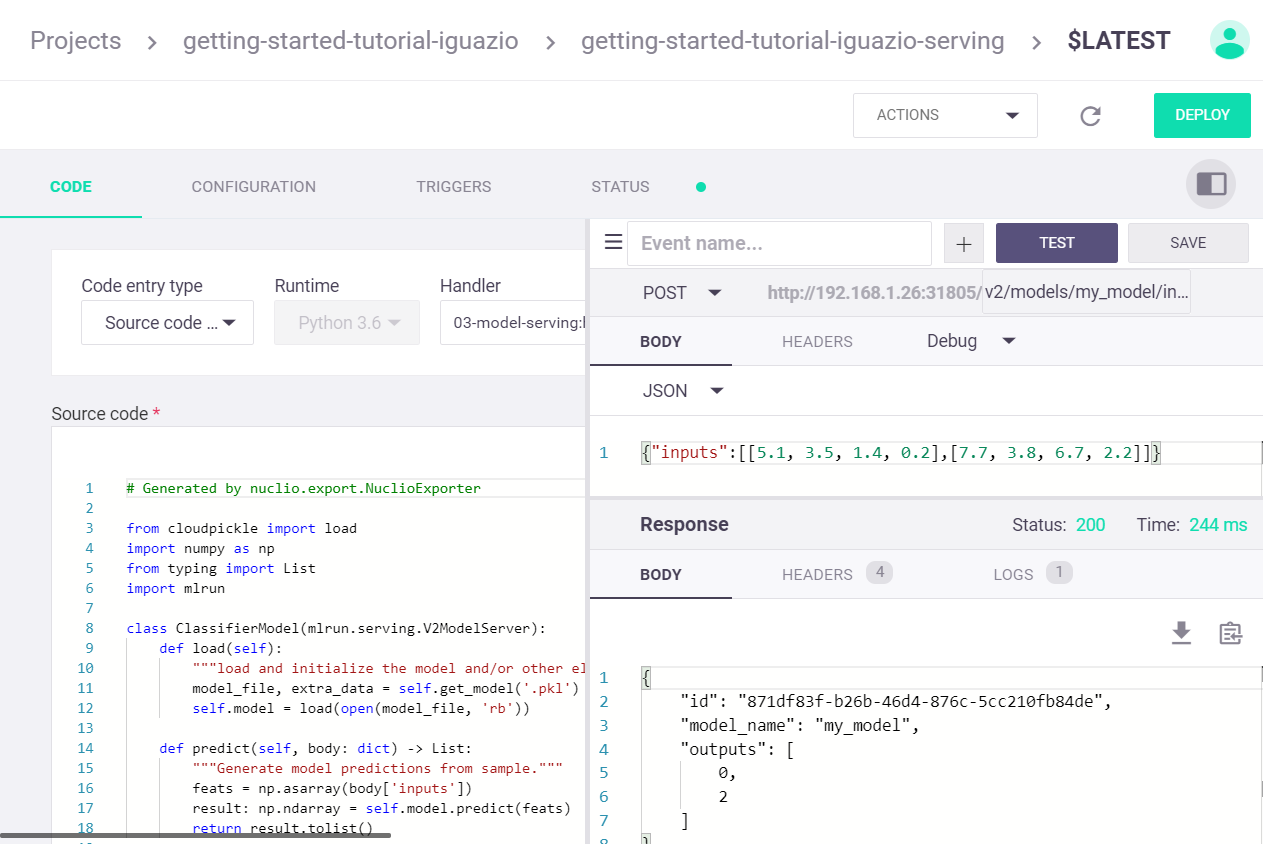
my_data = '''{"inputs":[[5.1, 3.5, 1.4, 0.2],[7.7, 3.8, 6.7, 2.2]]}'''
server = serving_fn.to_mock_server()
server.test("/v2/models/my_model/infer", body=my_data)
> 2022-02-08 19:58:44,716 [info] model my_model was loaded
> 2022-02-08 19:58:44,716 [info] Loaded ['my_model']
{'id': '97ed827394c24011bc2d95a001f7c372',
'model_name': 'my_model',
'outputs': [0, 2]}
Building and Deploying the Serving Function¶
Use the deploy method of the MLRun serving function to build and deploy a Nuclio serving function from your serving-function code.
function_address = serving_fn.deploy()
> 2022-02-08 19:58:50,645 [info] Starting remote function deploy
2022-02-08 19:58:51 (info) Deploying function
2022-02-08 19:58:51 (info) Building
2022-02-08 19:58:52 (info) Staging files and preparing base images
2022-02-08 19:58:52 (info) Building processor image
2022-02-08 19:59:47 (info) Build complete
> 2022-02-08 19:59:52,828 [info] successfully deployed function: {'internal_invocation_urls': ['nuclio-getting-started-admin-serving.default-tenant.svc.cluster.local:8080'], 'external_invocation_urls': ['getting-started-admin-serving-getting-started-admin.default-tenant.app.yh41.iguazio-cd1.com/']}
Step 4: Using the Live Model-Serving Function¶
After the function is deployed successfully, the serving function has a new HTTP endpoint for handling serving requests.
The example tutorial serving function receives HTTP prediction (inference) requests on this endpoint;
calls the infer method to get the requested predictions; and returns the results on the same endpoint.
print (f'The address for the function is {function_address} \n')
!curl $function_address
The address for the function is http://getting-started-admin-serving-getting-started-admin.default-tenant.app.yh41.iguazio-cd1.com/
{"name": "ModelRouter", "version": "v2", "extensions": []}
Testing the Model Server¶
Test your model server by sending data for inference.
The invoke serving-function method enables programmatic testing of the serving function.
For model inference (predictions), specify the model name followed by infer:
/v2/models/{model_name}/infer
For complete model-service API commands — such as for list models (models), get model health (ready), and model explanation (explain) — see the MLRun documentation.
serving_fn.invoke('/v2/models/my_model/infer', my_data)
> 2022-02-08 19:59:53,584 [info] invoking function: {'method': 'POST', 'path': 'http://nuclio-getting-started-admin-serving.default-tenant.svc.cluster.local:8080/v2/models/my_model/infer'}
{'id': '3fe451d7-20d8-4813-a7d4-292ceeaca98c',
'model_name': 'my_model',
'outputs': [0, 2]}
Step 5: Viewing the Nuclio Serving Function on the Dashboard¶
On the Projects dashboard page, select the project and then select “Real-time functions (Nuclio)”.
Done!¶
Congratulation! You’ve completed Part 3 of the MLRun getting-started tutorial. Proceed to Part 4: ML Pipeline to learn how to create an automated pipeline for your project.