
Dask distributed runtime
Contents
Dask distributed runtime#

Dask overview#
Source: Dask docs
Dask is a flexible library for parallel computing in Python.
Dask is composed of two parts:
Dynamic task scheduling optimized for computation. This is similar to Airflow, Luigi, Celery, or Make, but optimized for interactive computational workloads.
“Big Data” collections like parallel arrays, dataframes, and lists that extend common interfaces like NumPy, Pandas, or Python iterators to larger-than-memory or distributed environments. These parallel collections run on top of dynamic task schedulers.
Dask emphasizes the following virtues:
Familiar: Provides parallelized NumPy array and Pandas DataFrame objects
Flexible: Provides a task scheduling interface for more custom workloads and integration with other projects.
Native: Enables distributed computing in pure Python with access to the PyData stack.
Fast: Operates with low overhead, low latency, and minimal serialization necessary for fast numerical algorithms
Scales up: Runs resiliently on clusters with 1000s of cores
Scales down: Trivial to set up and run on a laptop in a single process
Responsive: Designed with interactive computing in mind, it provides rapid feedback and diagnostics to aid humans
Dask collections and schedulers

Dask DataFrame mimics Pandas#
import pandas as pd import dask.dataframe as dd
df = pd.read_csv('2015-01-01.csv') df = dd.read_csv('2015-*-*.csv')
df.groupby(df.user_id).value.mean() df.groupby(df.user_id).value.mean().compute()
Dask Array mimics NumPy - documentation
import numpy as np import dask.array as da
f = h5py.File('myfile.hdf5') f = h5py.File('myfile.hdf5')
x = np.array(f['/small-data']) x = da.from_array(f['/big-data'],
chunks=(1000, 1000))
x - x.mean(axis=1) x - x.mean(axis=1).compute()
Dask Bag mimics iterators, Toolz, and PySpark - documentation
import dask.bag as db
b = db.read_text('2015-*-*.json.gz').map(json.loads)
b.pluck('name').frequencies().topk(10, lambda pair: pair[1]).compute()
Dask Delayed mimics for loops and wraps custom code - documentation
from dask import delayed
L = []
for fn in filenames: # Use for loops to build up computation
data = delayed(load)(fn) # Delay execution of function
L.append(delayed(process)(data)) # Build connections between variables
result = delayed(summarize)(L)
result.compute()
The concurrent.futures interface provides general submission of custom tasks: - documentation
from dask.distributed import Client
client = Client('scheduler:port')
futures = []
for fn in filenames:
future = client.submit(load, fn)
futures.append(future)
summary = client.submit(summarize, futures)
summary.result()
Dask.distributed
#
Dask.distributed is a lightweight library for distributed computing in Python. It extends both the concurrent.futures and dask APIs to moderate sized clusters.
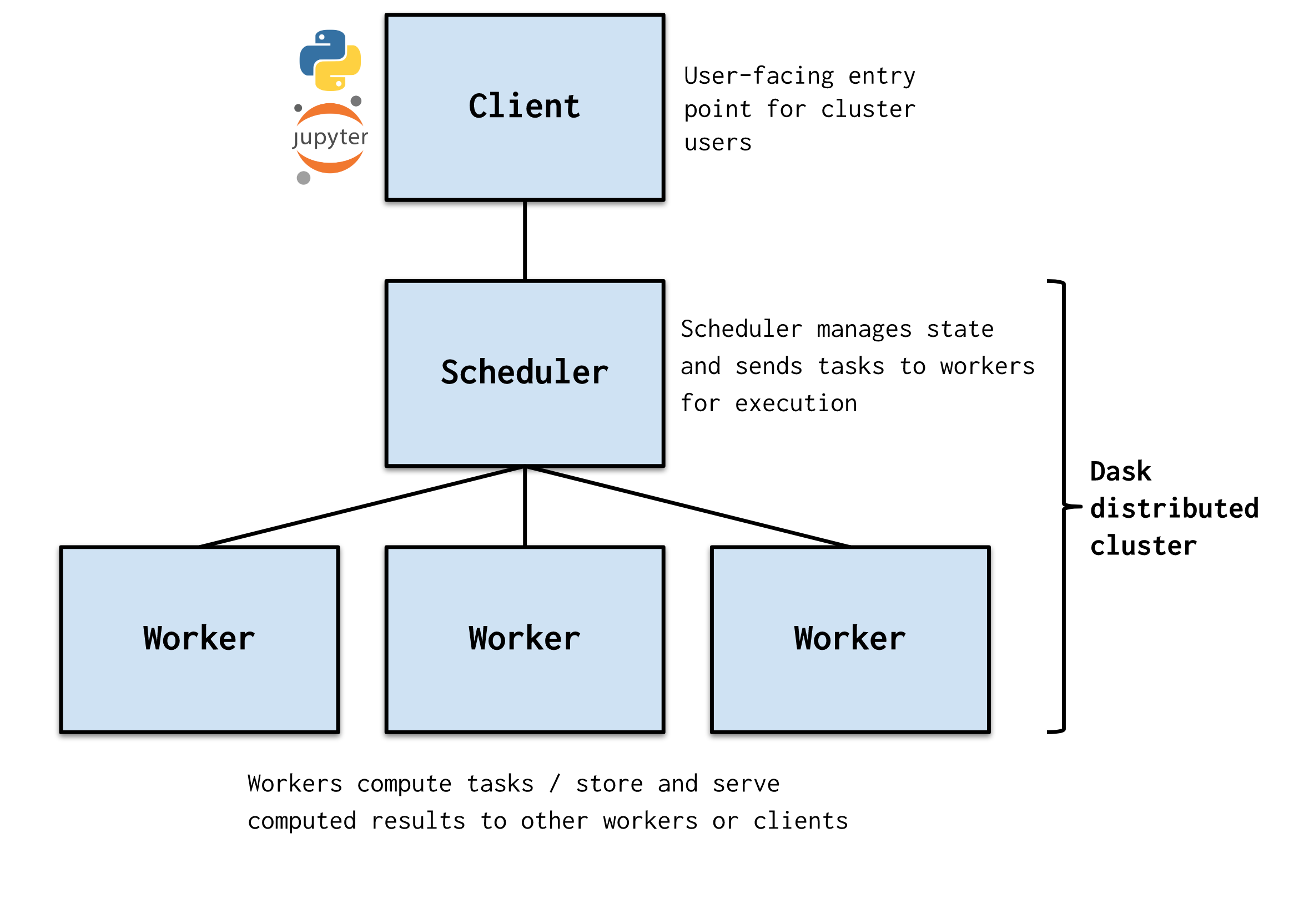
Motivation#
Distributed serves to complement the existing PyData analysis stack. In particular it meets the following needs:
Low latency: Each task suffers about 1ms of overhead. A small computation and network roundtrip can complete in less than 10ms.
Peer-to-peer data sharing: Workers communicate with each other to share data. This removes central bottlenecks for data transfer.
Complex Scheduling: Supports complex workflows (not just map/filter/reduce) which are necessary for sophisticated algorithms used in nd-arrays, machine learning, image processing, and statistics.
Pure Python: Built in Python using well-known technologies. This eases installation, improves efficiency (for Python users), and simplifies debugging.
Data Locality: Scheduling algorithms cleverly execute computations where data lives. This minimizes network traffic and improves efficiency.
Familiar APIs: Compatible with the concurrent.futures API in the Python standard library. Compatible with dask API for parallel algorithms
Easy Setup: As a Pure Python package distributed is pip installable and easy to set up on your own cluster.
Architecture#
Dask.distributed is a centrally managed, distributed, dynamic task scheduler. The central dask-scheduler process coordinates the actions of several dask-worker processes spread across multiple machines and the concurrent requests of several clients.
The scheduler is asynchronous and event driven, simultaneously responding to requests for computation from multiple clients and tracking the progress of multiple workers. The event-driven and asynchronous nature makes it flexible to concurrently handle a variety of workloads coming from multiple users at the same time while also handling a fluid worker population with failures and additions. Workers communicate amongst each other for bulk data transfer over TCP.
Internally the scheduler tracks all work as a constantly changing directed acyclic graph of tasks. A task is a Python function operating on Python objects, which can be the results of other tasks. This graph of tasks grows as users submit more computations, fills out as workers complete tasks, and shrinks as users leave or become disinterested in previous results.
Users interact by connecting a local Python session to the scheduler and submitting work, either by individual calls to the simple interface client.submit(function, *args, **kwargs) or by using the large data collections and parallel algorithms of the parent dask library. The collections in the dask library like dask.array and dask.dataframe provide easy access to sophisticated algorithms and familiar APIs like NumPy and Pandas, while the simple client.submit interface provides users with custom control when they want to break out of canned “big data” abstractions and submit fully custom workloads.
~5X Faster with Dask#
Short example which demonstrates the power of Dask, in this notebook we will preform the following:
Generate random text files
Process the file by sorting and counting it’s content
Compare run times
Generate random text files#
import random
import string
import os
from collections import Counter
from dask.distributed import Client
import warnings
warnings.filterwarnings('ignore')
def generate_big_random_letters(filename, size):
"""
generate big random letters/alphabets to a file
:param filename: the filename
:param size: the size in bytes
:return: void
"""
chars = ''.join([random.choice(string.ascii_letters) for i in range(size)]) #1
with open(filename, 'w') as f:
f.write(chars)
pass
PATH = '/User/howto/dask/random_files'
SIZE = 10000000
for i in range(100):
generate_big_random_letters(filename = PATH + '/file_' + str(i) + '.txt',
size = SIZE)
Setfunction for benchmark#
def count_letters(path):
"""
count letters in text file
:param path: path to file
"""
# open file in read mode
file = open(path, "r")
# read the content of file
data = file.read()
# sort file
sorted_file = sorted(data)
# count file
number_of_characters = len(sorted_file)
return number_of_characters
def process_files(path):
"""
list file and count letters
:param path: path to folder with files
"""
num_list = []
files = os.listdir(path)
for file in files:
cnt = count_letters(os.path.join(path, file))
num_list.append(cnt)
l = num_list
return print("done!")
Sort & count number of letters with Python#
%%time
PATH = '/User/howto/dask/random_files/'
process_files(PATH)
done!
CPU times: user 2min 19s, sys: 9.31 s, total: 2min 29s
Wall time: 2min 32s
Sort & count number of letters with Dask#
# get the dask client address
client = Client()
# list all files in folder
files = [PATH + x for x in os.listdir(PATH)]
%%time
# run the count_letter function on a list of files while using multiple workers
a = client.map(count_letters, files)
CPU times: user 13.2 ms, sys: 983 µs, total: 14.2 ms
Wall time: 12.2 ms
%%time
# gather results
l = client.gather(a)
CPU times: user 3.39 s, sys: 533 ms, total: 3.92 s
Wall time: 40 s