
Quick Start Tutorial
Contents
Quick Start Tutorial#
How to easily Train and Deploy Models to Production with MLRun
This notebook provides a quick overview of developing and deploying machine learning applications to production using MLRun MLOps orchestration framework. Watch the video for this tutorial.
Tutorial steps:
Install MLRun package and dependencies:
Before you start, make sure MLRun client package is installed (pip install mlrun) and the environment is set (pointing to a local or Kubernetes based MLRun service).
# verify the sklearn version (restart the notebook after the install), run only once
!pip install scikit-learn~=1.0.0
Requirement already satisfied: scikit-learn~=1.0.0 in /opt/conda/lib/python3.8/site-packages (1.0.2)
Requirement already satisfied: joblib>=0.11 in /opt/conda/lib/python3.8/site-packages (from scikit-learn~=1.0.0) (1.0.1)
Requirement already satisfied: scipy>=1.1.0 in /opt/conda/lib/python3.8/site-packages (from scikit-learn~=1.0.0) (1.6.3)
Requirement already satisfied: numpy>=1.14.6 in /opt/conda/lib/python3.8/site-packages (from scikit-learn~=1.0.0) (1.20.2)
Requirement already satisfied: threadpoolctl>=2.0.0 in /opt/conda/lib/python3.8/site-packages (from scikit-learn~=1.0.0) (2.1.0)
WARNING: You are using pip version 22.0.4; however, version 22.2.2 is available.
You should consider upgrading via the '/opt/conda/bin/python -m pip install --upgrade pip' command.
import mlrun
# check if we are attached to k8s for running remote (container) jobs
no_k8s = False if mlrun.mlconf.namespace else True
Define MLRun project and ML functions#
MLRun Project is a container for all your work on a particular activity or application. Projects host functions, workflow,
artifacts, secrets, and more. Projects have access control and can be accessed by one or more users; they are usually associated with a GIT and interact with CI/CD frameworks for automation.
See the MLRun Projects documentation.
MLRun Serverless Function specify the source code, base image, extra package requirements, runtime engine kind, and desired resources (cpu, gpu, mem, storage, …). The runtime engines (local, job, Nuclio, Spark, etc.) automatically transform the function code and spec into fully managed and elastic services that run over Kubernetes.
Function source code can come from a single file (.py, .ipynb, etc.) or a full archive (git, zip, tar). MLRun can execute an entire file/notebook or specific function classes/handlers.
Functions in this project:
gen_breast_cancer.py - Breast Cancer data generator
trainer.py - Model Training function
serving.py - Model serving function
Registering the function code and basic info in the project:
project = mlrun.new_project("breast-cancer", "src/", user_project=True, init_git=True)
project.set_function("gen_breast_cancer.py", "get-data", image="mlrun/mlrun")
project.set_function("trainer.py", "trainer",
handler="train", image="mlrun/mlrun")
project.set_function("serving.py", "serving", image="mlrun/mlrun", kind="serving")
project.save()
<mlrun.projects.project.MlrunProject at 0x7f7c523d0580>
The project spec (project.yaml) is saved to the project root dir for use by CI/CD and automation frameworks.
Run data processing function and log artifacts#
Functions are executed (using the CLI or SDK run command) with an optional handler, various params, inputs and resource requirements. This generates a run object that can be tracked through the CLI, UI, and SDK. Multiple functions can be executed and tracked as part of a multi-stage pipeline (workflow).
When a function has additional package
requirementsor need to include the content of asourcearchive, you must first build the function using theproject.build_function()method.
The local flag indicates if the function is executed locally or “teleported” and executed in the Kubernetes cluster. The execution progress and results can be viewed in the UI (see hyperlinks below).
Run using the SDK:
gen_data_run = project.run_function("get-data", params={"format": "csv"}, local=True)
> 2022-08-24 08:59:21,463 [warning] it is recommended to use k8s secret (specify secret_name), specifying the aws_access_key/aws_secret_key directly is unsafe
> 2022-08-24 08:59:21,471 [info] starting run get-data uid=70b13f76e7304f1fb104d348e4ac29ad DB=http://mlrun-api:8080
> 2022-08-24 08:59:21,569 [info] handler was not provided running main (src/gen_breast_cancer.py)
> 2022-08-24 08:59:28,967 [info] logging run results to: http://mlrun-api:8080
> 2022-08-24 08:59:29,164 [info] saving breast cancer dataframe
| project | uid | iter | start | state | name | labels | inputs | parameters | results | artifacts |
|---|---|---|---|---|---|---|---|---|---|---|
| breast-cancer-jovyan | 0 | Aug 24 08:59:28 | completed | get-data | kind= owner=jovyan host=mlrun-jupyter-6b78bf965-knkrt |
format=csv |
label_column=label |
dataset |
> 2022-08-24 08:59:31,080 [info] run executed, status=completed
Run using the CLI (command line):
The functions can also be invoked using the following CLI command (see help with: mlrun run --help):
mlrun run -f gen-breast-cancer --local
Print the run state and outputs:
gen_data_run.state()
'completed'
gen_data_run.outputs
{'label_column': 'label',
'dataset': 'store://artifacts/breast-cancer-jovyan/get-data_dataset:70b13f76e7304f1fb104d348e4ac29ad'}
Print the output dataset artifact (DataItem object) as dataframe
gen_data_run.artifact("dataset").as_df().head()
| mean radius | mean texture | mean perimeter | mean area | mean smoothness | mean compactness | mean concavity | mean concave points | mean symmetry | mean fractal dimension | ... | worst texture | worst perimeter | worst area | worst smoothness | worst compactness | worst concavity | worst concave points | worst symmetry | worst fractal dimension | label | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 17.99 | 10.38 | 122.80 | 1001.0 | 0.11840 | 0.27760 | 0.3001 | 0.14710 | 0.2419 | 0.07871 | ... | 17.33 | 184.60 | 2019.0 | 0.1622 | 0.6656 | 0.7119 | 0.2654 | 0.4601 | 0.11890 | 0 |
| 1 | 20.57 | 17.77 | 132.90 | 1326.0 | 0.08474 | 0.07864 | 0.0869 | 0.07017 | 0.1812 | 0.05667 | ... | 23.41 | 158.80 | 1956.0 | 0.1238 | 0.1866 | 0.2416 | 0.1860 | 0.2750 | 0.08902 | 0 |
| 2 | 19.69 | 21.25 | 130.00 | 1203.0 | 0.10960 | 0.15990 | 0.1974 | 0.12790 | 0.2069 | 0.05999 | ... | 25.53 | 152.50 | 1709.0 | 0.1444 | 0.4245 | 0.4504 | 0.2430 | 0.3613 | 0.08758 | 0 |
| 3 | 11.42 | 20.38 | 77.58 | 386.1 | 0.14250 | 0.28390 | 0.2414 | 0.10520 | 0.2597 | 0.09744 | ... | 26.50 | 98.87 | 567.7 | 0.2098 | 0.8663 | 0.6869 | 0.2575 | 0.6638 | 0.17300 | 0 |
| 4 | 20.29 | 14.34 | 135.10 | 1297.0 | 0.10030 | 0.13280 | 0.1980 | 0.10430 | 0.1809 | 0.05883 | ... | 16.67 | 152.20 | 1575.0 | 0.1374 | 0.2050 | 0.4000 | 0.1625 | 0.2364 | 0.07678 | 0 |
5 rows × 31 columns
Use MLRun built-in marketplace functions (data analysis)#
You can import an ML function from the mlrun public marketplace or private repositories and use them in your project. Let’s import and use a data analysis function:
# import the function
describe = mlrun.import_function('hub://describe')
See the
describefunction usage instructions in the marketplace or by typingdescribe.doc()
Analyze the dataset using the describe function (run on the Kubernetes cluster):
describe_run = describe.run(params={'label_column': 'label'},
inputs={"table": gen_data_run.outputs['dataset']}, local=no_k8s)
> 2022-08-24 08:59:32,582 [warning] it is recommended to use k8s secret (specify secret_name), specifying the aws_access_key/aws_secret_key directly is unsafe
> 2022-08-24 08:59:32,596 [info] starting run describe-analyze uid=f663a67686ed4cff81b138ba730ebd08 DB=http://mlrun-api:8080
> 2022-08-24 08:59:33,018 [info] Job is running in the background, pod: describe-analyze-stxpl
> 2022-08-24 08:59:46,528 [info] The data set named dataset is updated
> 2022-08-24 08:59:46,555 [info] run executed, status=completed
final state: completed
| project | uid | iter | start | state | name | labels | inputs | parameters | results | artifacts |
|---|---|---|---|---|---|---|---|---|---|---|
| breast-cancer-jovyan | 0 | Aug 24 08:59:39 | completed | describe-analyze | kind=job owner=jovyan mlrun/client_version=1.1.0-rc24 host=describe-analyze-stxpl |
table |
label_column=label |
describe-csv plots/hist.html histograms scatter-2d violin imbalance imbalance-weights-vec correlation-matrix-csv correlation |
> 2022-08-24 08:59:52,505 [info] run executed, status=completed
View the results in MLRun UI:

# view generated artifacts (charts)
describe_run.outputs
{'describe-csv': 's3://mlrun/describe-analyze/0/describe-csv.csv',
'plots/hist.html': 's3://mlrun/describe-analyze/0/plots/hist.html',
'histograms': 's3://mlrun/describe-analyze/0/histograms.html',
'scatter-2d': 's3://mlrun/describe-analyze/0/scatter-2d.html',
'violin': 's3://mlrun/describe-analyze/0/violin.html',
'imbalance': 's3://mlrun/describe-analyze/0/imbalance.html',
'imbalance-weights-vec': 's3://mlrun/describe-analyze/0/imbalance-weights-vec.csv',
'correlation-matrix-csv': 's3://mlrun/describe-analyze/0/correlation-matrix-csv.csv',
'correlation': 's3://mlrun/describe-analyze/0/correlation.html'}
# view an artifact in Jupyter
describe_run.artifact("histograms").show()
Train, track, and register models#
in the trainer.py (view) code file, notice the line:
apply_mlrun(model=model, model_name="my_model", x_test=x_test, y_test=y_test)
apply_mlrun() accepts the model object and various optional parameters and automatically logs/registers the model
along with its metrics and various charts.
When specifying the x_test and y_test data it generates various plots and calculations to evaluate the model.
Metadata and parameters are automatically recorded (from MLRun context object) and don’t need to be specified.
trainer_run = project.run_function(
"trainer",
inputs={"dataset": gen_data_run.outputs["dataset"]},
params = {"n_estimators": 100, "learning_rate": 1e-1, "max_depth": 3},
local=True
)
> 2022-08-24 08:59:52,694 [warning] it is recommended to use k8s secret (specify secret_name), specifying the aws_access_key/aws_secret_key directly is unsafe
> 2022-08-24 08:59:52,702 [info] starting run trainer-train uid=86586a70f9134c66a4e404f02ad92bd8 DB=http://mlrun-api:8080
| project | uid | iter | start | state | name | labels | inputs | parameters | results | artifacts |
|---|---|---|---|---|---|---|---|---|---|---|
| breast-cancer-jovyan | 0 | Aug 24 08:59:52 | completed | trainer-train | kind= owner=jovyan host=mlrun-jupyter-6b78bf965-knkrt |
dataset |
n_estimators=100 learning_rate=0.1 max_depth=3 |
accuracy=0.956140350877193 f1_score=0.965034965034965 precision_score=0.9583333333333334 recall_score=0.971830985915493 |
feature-importance test_set confusion-matrix roc-curves calibration-curve model |
> 2022-08-24 08:59:57,788 [info] run executed, status=completed
Results and artifacts are generated and tracked automatically by MLRun:
trainer_run.outputs
{'accuracy': 0.956140350877193,
'f1_score': 0.965034965034965,
'precision_score': 0.9583333333333334,
'recall_score': 0.971830985915493,
'feature-importance': 's3://mlrun/trainer-train/0/feature-importance.html',
'test_set': 'store://artifacts/breast-cancer-jovyan/trainer-train_test_set:86586a70f9134c66a4e404f02ad92bd8',
'confusion-matrix': 's3://mlrun/trainer-train/0/confusion-matrix.html',
'roc-curves': 's3://mlrun/trainer-train/0/roc-curves.html',
'calibration-curve': 's3://mlrun/trainer-train/0/calibration-curve.html',
'model': 'store://artifacts/breast-cancer-jovyan/cancer_classifier:86586a70f9134c66a4e404f02ad92bd8'}
trainer_run.artifact('feature-importance').show()
Hyper-parameter tuning and model/experiment comparison#
Run a GridSearch with a couple of parameters, and select the best run with respect to the max accuracy.
(read more about MLRun Hyper-Param and Iterative jobs).
For basic usage you can run the hyperparameters tuning job by using the arguments:
hyperparamsfor the hyperparameters options and values of choice.selectorfor specifying how to select the best model.
hp_tuning_run = project.run_function(
"trainer",
inputs={"dataset": gen_data_run.outputs["dataset"]},
hyperparams={
"n_estimators": [10, 100, 1000],
"learning_rate": [1e-1, 1e-3],
"max_depth": [2, 8]
},
selector="max.accuracy",
local=no_k8s
)
> 2022-08-24 08:59:58,045 [info] starting run trainer-train uid=ada280c6b47b44c090329c5245e4acd6 DB=http://mlrun-api:8080
> 2022-08-24 08:59:58,321 [info] Job is running in the background, pod: trainer-train-wq7tb
> 2022-08-24 09:00:48,293 [info] best iteration=3, used criteria max.accuracy
> 2022-08-24 09:00:48,868 [info] run executed, status=completed
final state: completed
| project | uid | iter | start | state | name | labels | inputs | parameters | results | artifacts |
|---|---|---|---|---|---|---|---|---|---|---|
| breast-cancer-jovyan | 0 | Aug 24 09:00:04 | completed | trainer-train | kind=job owner=jovyan mlrun/client_version=1.1.0-rc24 |
dataset |
best_iteration=3 accuracy=0.9649122807017544 f1_score=0.9722222222222222 precision_score=0.958904109589041 recall_score=0.9859154929577465 |
feature-importance test_set confusion-matrix roc-curves calibration-curve model iteration_results parallel_coordinates |
> 2022-08-24 09:00:57,950 [info] run executed, status=completed
View Hyper-param results and the selected run in the MLRun UI:
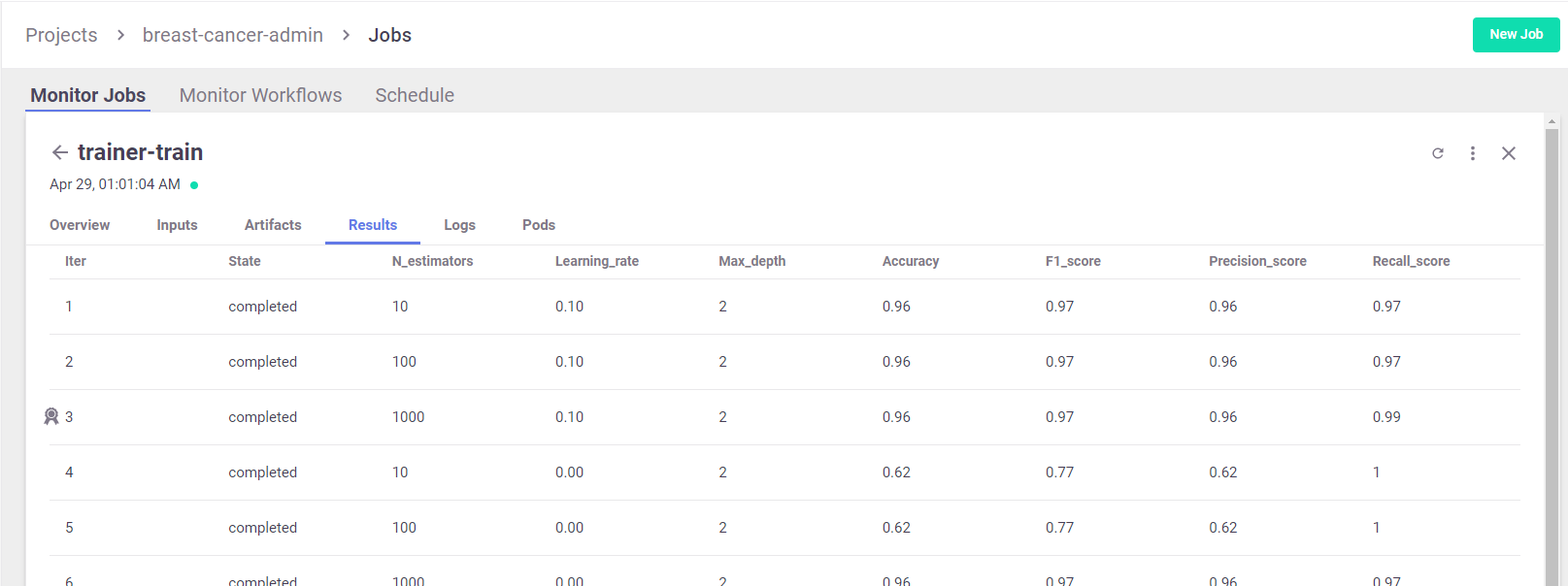
Interactive Parallel Coordinates Plot:
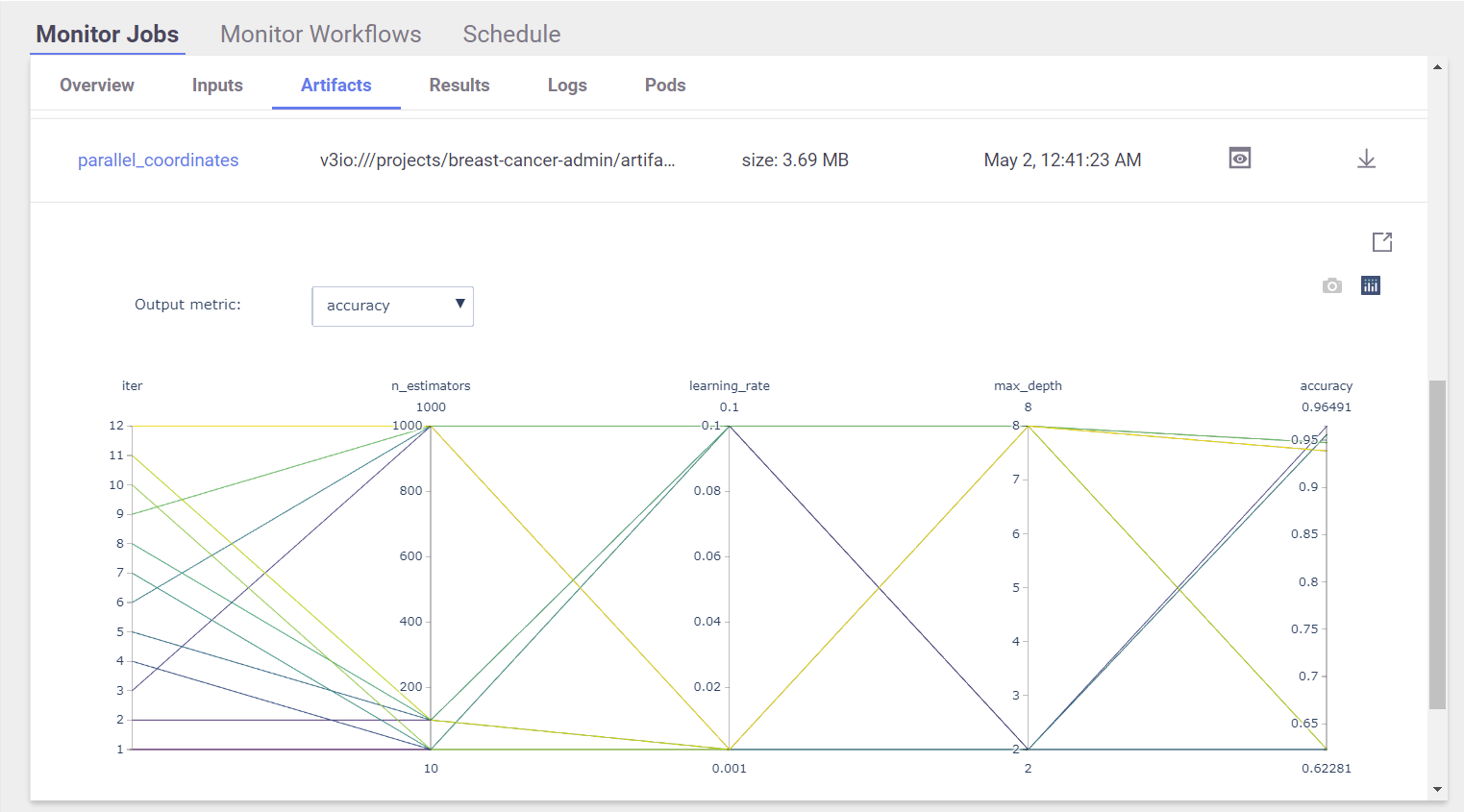
List the generated models and compare the different runs:
hp_tuning_run.outputs
{'best_iteration': 3,
'accuracy': 0.9649122807017544,
'f1_score': 0.9722222222222222,
'precision_score': 0.958904109589041,
'recall_score': 0.9859154929577465,
'feature-importance': 's3://mlrun/trainer-train/3/feature-importance.html',
'test_set': 'store://artifacts/breast-cancer-jovyan/trainer-train_test_set:ada280c6b47b44c090329c5245e4acd6',
'confusion-matrix': 's3://mlrun/trainer-train/3/confusion-matrix.html',
'roc-curves': 's3://mlrun/trainer-train/3/roc-curves.html',
'calibration-curve': 's3://mlrun/trainer-train/3/calibration-curve.html',
'model': 'store://artifacts/breast-cancer-jovyan/cancer_classifier:ada280c6b47b44c090329c5245e4acd6',
'iteration_results': 's3://mlrun/trainer-train/0/iteration_results.csv',
'parallel_coordinates': 's3://mlrun/trainer-train/0/parallel_coordinates.html'}
# list the models in the project (can apply filters)
models = project.list_models()
for model in models:
print(f"uri: {model.uri}, metrics: {model.metrics}")
uri: store://models/breast-cancer-jovyan/cancer_classifier#0:b6d617eef1f643579df6a6f864dabae6, metrics: {'accuracy': 0.956140350877193, 'f1_score': 0.965034965034965, 'precision_score': 0.9583333333333334, 'recall_score': 0.971830985915493}
uri: store://models/breast-cancer-jovyan/cancer_classifier#1:1ae77cbb2feb49e587b244af6a1c94f4, metrics: {'accuracy': 0.956140350877193, 'f1_score': 0.965034965034965, 'precision_score': 0.9583333333333334, 'recall_score': 0.971830985915493}
uri: store://models/breast-cancer-jovyan/cancer_classifier#2:1ae77cbb2feb49e587b244af6a1c94f4, metrics: {'accuracy': 0.956140350877193, 'f1_score': 0.965034965034965, 'precision_score': 0.9583333333333334, 'recall_score': 0.971830985915493}
uri: store://models/breast-cancer-jovyan/cancer_classifier#3:1ae77cbb2feb49e587b244af6a1c94f4, metrics: {'accuracy': 0.9649122807017544, 'f1_score': 0.9722222222222222, 'precision_score': 0.958904109589041, 'recall_score': 0.9859154929577465}
uri: store://models/breast-cancer-jovyan/cancer_classifier#4:1ae77cbb2feb49e587b244af6a1c94f4, metrics: {'accuracy': 0.6228070175438597, 'f1_score': 0.7675675675675676, 'precision_score': 0.6228070175438597, 'recall_score': 1.0}
uri: store://models/breast-cancer-jovyan/cancer_classifier#5:1ae77cbb2feb49e587b244af6a1c94f4, metrics: {'accuracy': 0.6228070175438597, 'f1_score': 0.7675675675675676, 'precision_score': 0.6228070175438597, 'recall_score': 1.0}
uri: store://models/breast-cancer-jovyan/cancer_classifier#6:1ae77cbb2feb49e587b244af6a1c94f4, metrics: {'accuracy': 0.956140350877193, 'f1_score': 0.965034965034965, 'precision_score': 0.9583333333333334, 'recall_score': 0.971830985915493}
uri: store://models/breast-cancer-jovyan/cancer_classifier#7:1ae77cbb2feb49e587b244af6a1c94f4, metrics: {'accuracy': 0.9385964912280702, 'f1_score': 0.951048951048951, 'precision_score': 0.9444444444444444, 'recall_score': 0.9577464788732394}
uri: store://models/breast-cancer-jovyan/cancer_classifier#8:1ae77cbb2feb49e587b244af6a1c94f4, metrics: {'accuracy': 0.9473684210526315, 'f1_score': 0.9577464788732394, 'precision_score': 0.9577464788732394, 'recall_score': 0.9577464788732394}
uri: store://models/breast-cancer-jovyan/cancer_classifier#9:1ae77cbb2feb49e587b244af6a1c94f4, metrics: {'accuracy': 0.9473684210526315, 'f1_score': 0.9577464788732394, 'precision_score': 0.9577464788732394, 'recall_score': 0.9577464788732394}
uri: store://models/breast-cancer-jovyan/cancer_classifier#10:1ae77cbb2feb49e587b244af6a1c94f4, metrics: {'accuracy': 0.6228070175438597, 'f1_score': 0.7675675675675676, 'precision_score': 0.6228070175438597, 'recall_score': 1.0}
uri: store://models/breast-cancer-jovyan/cancer_classifier#11:1ae77cbb2feb49e587b244af6a1c94f4, metrics: {'accuracy': 0.6228070175438597, 'f1_score': 0.7675675675675676, 'precision_score': 0.6228070175438597, 'recall_score': 1.0}
uri: store://models/breast-cancer-jovyan/cancer_classifier#12:1ae77cbb2feb49e587b244af6a1c94f4, metrics: {'accuracy': 0.9385964912280702, 'f1_score': 0.951048951048951, 'precision_score': 0.9444444444444444, 'recall_score': 0.9577464788732394}
# to view the full model object use:
# print(models[0].to_yaml())
# compare the runs (generate interactive parallel coordinates plot and a table)
project.list_runs(name="trainer-train", iter=True).compare()
| uid | iter | start | state | name | parameters | results |
|---|---|---|---|---|---|---|
| 12 | Aug 24 09:00:37 | completed | trainer-train | n_estimators=1000 learning_rate=0.001 max_depth=8 |
accuracy=0.9385964912280702 f1_score=0.951048951048951 precision_score=0.9444444444444444 recall_score=0.9577464788732394 |
|
| 11 | Aug 24 09:00:33 | completed | trainer-train | n_estimators=100 learning_rate=0.001 max_depth=8 |
accuracy=0.6228070175438597 f1_score=0.7675675675675676 precision_score=0.6228070175438597 recall_score=1.0 |
|
| 10 | Aug 24 09:00:31 | completed | trainer-train | n_estimators=10 learning_rate=0.001 max_depth=8 |
accuracy=0.6228070175438597 f1_score=0.7675675675675676 precision_score=0.6228070175438597 recall_score=1.0 |
|
| 9 | Aug 24 09:00:28 | completed | trainer-train | n_estimators=1000 learning_rate=0.1 max_depth=8 |
accuracy=0.9385964912280702 f1_score=0.951048951048951 precision_score=0.9444444444444444 recall_score=0.9577464788732394 |
|
| 8 | Aug 24 09:00:26 | completed | trainer-train | n_estimators=100 learning_rate=0.1 max_depth=8 |
accuracy=0.9385964912280702 f1_score=0.951048951048951 precision_score=0.9444444444444444 recall_score=0.9577464788732394 |
|
| 7 | Aug 24 09:00:24 | completed | trainer-train | n_estimators=10 learning_rate=0.1 max_depth=8 |
accuracy=0.9385964912280702 f1_score=0.951048951048951 precision_score=0.9444444444444444 recall_score=0.9577464788732394 |
|
| 6 | Aug 24 09:00:19 | completed | trainer-train | n_estimators=1000 learning_rate=0.001 max_depth=2 |
accuracy=0.956140350877193 f1_score=0.965034965034965 precision_score=0.9583333333333334 recall_score=0.971830985915493 |
|
| 5 | Aug 24 09:00:17 | completed | trainer-train | n_estimators=100 learning_rate=0.001 max_depth=2 |
accuracy=0.6228070175438597 f1_score=0.7675675675675676 precision_score=0.6228070175438597 recall_score=1.0 |
|
| 4 | Aug 24 09:00:16 | completed | trainer-train | n_estimators=10 learning_rate=0.001 max_depth=2 |
accuracy=0.6228070175438597 f1_score=0.7675675675675676 precision_score=0.6228070175438597 recall_score=1.0 |
|
| 3 | Aug 24 09:00:12 | completed | trainer-train | n_estimators=1000 learning_rate=0.1 max_depth=2 |
accuracy=0.9649122807017544 f1_score=0.9722222222222222 precision_score=0.958904109589041 recall_score=0.9859154929577465 |
|
| 2 | Aug 24 09:00:09 | completed | trainer-train | n_estimators=100 learning_rate=0.1 max_depth=2 |
accuracy=0.956140350877193 f1_score=0.965034965034965 precision_score=0.9583333333333334 recall_score=0.971830985915493 |
|
| 1 | Aug 24 09:00:05 | completed | trainer-train | n_estimators=10 learning_rate=0.1 max_depth=2 |
accuracy=0.956140350877193 f1_score=0.965034965034965 precision_score=0.9583333333333334 recall_score=0.971830985915493 |
|
| 1 | Aug 24 09:00:04 | completed | trainer-train | n_estimators=10 learning_rate=0.1 max_depth=2 |
accuracy=0.956140350877193 f1_score=0.965034965034965 precision_score=0.9583333333333334 recall_score=0.971830985915493 |
|
| 2 | Aug 24 09:00:04 | completed | trainer-train | n_estimators=100 learning_rate=0.1 max_depth=2 |
accuracy=0.956140350877193 f1_score=0.965034965034965 precision_score=0.9583333333333334 recall_score=0.971830985915493 |
|
| 3 | Aug 24 09:00:04 | completed | trainer-train | n_estimators=1000 learning_rate=0.1 max_depth=2 |
accuracy=0.9649122807017544 f1_score=0.9722222222222222 precision_score=0.958904109589041 recall_score=0.9859154929577465 |
|
| 4 | Aug 24 09:00:04 | completed | trainer-train | n_estimators=10 learning_rate=0.001 max_depth=2 |
accuracy=0.6228070175438597 f1_score=0.7675675675675676 precision_score=0.6228070175438597 recall_score=1.0 |
|
| 5 | Aug 24 09:00:04 | completed | trainer-train | n_estimators=100 learning_rate=0.001 max_depth=2 |
accuracy=0.6228070175438597 f1_score=0.7675675675675676 precision_score=0.6228070175438597 recall_score=1.0 |
|
| 6 | Aug 24 09:00:04 | completed | trainer-train | n_estimators=1000 learning_rate=0.001 max_depth=2 |
accuracy=0.956140350877193 f1_score=0.965034965034965 precision_score=0.9583333333333334 recall_score=0.971830985915493 |
|
| 7 | Aug 24 09:00:04 | completed | trainer-train | n_estimators=10 learning_rate=0.1 max_depth=8 |
accuracy=0.9385964912280702 f1_score=0.951048951048951 precision_score=0.9444444444444444 recall_score=0.9577464788732394 |
|
| 8 | Aug 24 09:00:04 | completed | trainer-train | n_estimators=100 learning_rate=0.1 max_depth=8 |
accuracy=0.9385964912280702 f1_score=0.951048951048951 precision_score=0.9444444444444444 recall_score=0.9577464788732394 |
|
| 9 | Aug 24 09:00:04 | completed | trainer-train | n_estimators=1000 learning_rate=0.1 max_depth=8 |
accuracy=0.9385964912280702 f1_score=0.951048951048951 precision_score=0.9444444444444444 recall_score=0.9577464788732394 |
|
| 10 | Aug 24 09:00:04 | completed | trainer-train | n_estimators=10 learning_rate=0.001 max_depth=8 |
accuracy=0.6228070175438597 f1_score=0.7675675675675676 precision_score=0.6228070175438597 recall_score=1.0 |
|
| 11 | Aug 24 09:00:04 | completed | trainer-train | n_estimators=100 learning_rate=0.001 max_depth=8 |
accuracy=0.6228070175438597 f1_score=0.7675675675675676 precision_score=0.6228070175438597 recall_score=1.0 |
|
| 12 | Aug 24 09:00:04 | completed | trainer-train | n_estimators=1000 learning_rate=0.001 max_depth=8 |
accuracy=0.9385964912280702 f1_score=0.951048951048951 precision_score=0.9444444444444444 recall_score=0.9577464788732394 |
|
| 0 | Aug 24 08:59:52 | completed | trainer-train | n_estimators=100 learning_rate=0.1 max_depth=3 |
accuracy=0.956140350877193 f1_score=0.965034965034965 precision_score=0.9583333333333334 recall_score=0.971830985915493 |
|
| 12 | Aug 24 08:42:59 | completed | trainer-train | n_estimators=1000 learning_rate=0.001 max_depth=8 |
accuracy=0.9385964912280702 f1_score=0.951048951048951 precision_score=0.9444444444444444 recall_score=0.9577464788732394 |
|
| 11 | Aug 24 08:42:57 | completed | trainer-train | n_estimators=100 learning_rate=0.001 max_depth=8 |
accuracy=0.6228070175438597 f1_score=0.7675675675675676 precision_score=0.6228070175438597 recall_score=1.0 |
|
| 10 | Aug 24 08:42:56 | completed | trainer-train | n_estimators=10 learning_rate=0.001 max_depth=8 |
accuracy=0.6228070175438597 f1_score=0.7675675675675676 precision_score=0.6228070175438597 recall_score=1.0 |
|
| 9 | Aug 24 08:42:53 | completed | trainer-train | n_estimators=1000 learning_rate=0.1 max_depth=8 |
accuracy=0.9473684210526315 f1_score=0.9577464788732394 precision_score=0.9577464788732394 recall_score=0.9577464788732394 |
|
| 8 | Aug 24 08:42:50 | completed | trainer-train | n_estimators=100 learning_rate=0.1 max_depth=8 |
accuracy=0.9473684210526315 f1_score=0.9577464788732394 precision_score=0.9577464788732394 recall_score=0.9577464788732394 |
|
| 7 | Aug 24 08:42:49 | completed | trainer-train | n_estimators=10 learning_rate=0.1 max_depth=8 |
accuracy=0.9385964912280702 f1_score=0.951048951048951 precision_score=0.9444444444444444 recall_score=0.9577464788732394 |
|
| 6 | Aug 24 08:42:45 | completed | trainer-train | n_estimators=1000 learning_rate=0.001 max_depth=2 |
accuracy=0.956140350877193 f1_score=0.965034965034965 precision_score=0.9583333333333334 recall_score=0.971830985915493 |
|
| 5 | Aug 24 08:42:43 | completed | trainer-train | n_estimators=100 learning_rate=0.001 max_depth=2 |
accuracy=0.6228070175438597 f1_score=0.7675675675675676 precision_score=0.6228070175438597 recall_score=1.0 |
|
| 4 | Aug 24 08:42:42 | completed | trainer-train | n_estimators=10 learning_rate=0.001 max_depth=2 |
accuracy=0.6228070175438597 f1_score=0.7675675675675676 precision_score=0.6228070175438597 recall_score=1.0 |
|
| 3 | Aug 24 08:42:37 | completed | trainer-train | n_estimators=1000 learning_rate=0.1 max_depth=2 |
accuracy=0.9649122807017544 f1_score=0.9722222222222222 precision_score=0.958904109589041 recall_score=0.9859154929577465 |
|
| 2 | Aug 24 08:42:35 | completed | trainer-train | n_estimators=100 learning_rate=0.1 max_depth=2 |
accuracy=0.956140350877193 f1_score=0.965034965034965 precision_score=0.9583333333333334 recall_score=0.971830985915493 |
|
| 1 | Aug 24 08:42:32 | completed | trainer-train | n_estimators=10 learning_rate=0.1 max_depth=2 |
accuracy=0.956140350877193 f1_score=0.965034965034965 precision_score=0.9583333333333334 recall_score=0.971830985915493 |
|
| 1 | Aug 24 08:42:32 | completed | trainer-train | n_estimators=10 learning_rate=0.1 max_depth=2 |
accuracy=0.956140350877193 f1_score=0.965034965034965 precision_score=0.9583333333333334 recall_score=0.971830985915493 |
|
| 2 | Aug 24 08:42:32 | completed | trainer-train | n_estimators=100 learning_rate=0.1 max_depth=2 |
accuracy=0.956140350877193 f1_score=0.965034965034965 precision_score=0.9583333333333334 recall_score=0.971830985915493 |
|
| 3 | Aug 24 08:42:32 | completed | trainer-train | n_estimators=1000 learning_rate=0.1 max_depth=2 |
accuracy=0.9649122807017544 f1_score=0.9722222222222222 precision_score=0.958904109589041 recall_score=0.9859154929577465 |
|
| 4 | Aug 24 08:42:32 | completed | trainer-train | n_estimators=10 learning_rate=0.001 max_depth=2 |
accuracy=0.6228070175438597 f1_score=0.7675675675675676 precision_score=0.6228070175438597 recall_score=1.0 |
|
| 5 | Aug 24 08:42:32 | completed | trainer-train | n_estimators=100 learning_rate=0.001 max_depth=2 |
accuracy=0.6228070175438597 f1_score=0.7675675675675676 precision_score=0.6228070175438597 recall_score=1.0 |
|
| 6 | Aug 24 08:42:32 | completed | trainer-train | n_estimators=1000 learning_rate=0.001 max_depth=2 |
accuracy=0.956140350877193 f1_score=0.965034965034965 precision_score=0.9583333333333334 recall_score=0.971830985915493 |
|
| 7 | Aug 24 08:42:32 | completed | trainer-train | n_estimators=10 learning_rate=0.1 max_depth=8 |
accuracy=0.9385964912280702 f1_score=0.951048951048951 precision_score=0.9444444444444444 recall_score=0.9577464788732394 |
|
| 8 | Aug 24 08:42:32 | completed | trainer-train | n_estimators=100 learning_rate=0.1 max_depth=8 |
accuracy=0.9473684210526315 f1_score=0.9577464788732394 precision_score=0.9577464788732394 recall_score=0.9577464788732394 |
|
| 9 | Aug 24 08:42:32 | completed | trainer-train | n_estimators=1000 learning_rate=0.1 max_depth=8 |
accuracy=0.9473684210526315 f1_score=0.9577464788732394 precision_score=0.9577464788732394 recall_score=0.9577464788732394 |
|
| 10 | Aug 24 08:42:32 | completed | trainer-train | n_estimators=10 learning_rate=0.001 max_depth=8 |
accuracy=0.6228070175438597 f1_score=0.7675675675675676 precision_score=0.6228070175438597 recall_score=1.0 |
|
| 11 | Aug 24 08:42:32 | completed | trainer-train | n_estimators=100 learning_rate=0.001 max_depth=8 |
accuracy=0.6228070175438597 f1_score=0.7675675675675676 precision_score=0.6228070175438597 recall_score=1.0 |
|
| 12 | Aug 24 08:42:32 | completed | trainer-train | n_estimators=1000 learning_rate=0.001 max_depth=8 |
accuracy=0.9385964912280702 f1_score=0.951048951048951 precision_score=0.9444444444444444 recall_score=0.9577464788732394 |
|
| 0 | Aug 24 08:42:24 | completed | trainer-train | n_estimators=100 learning_rate=0.1 max_depth=3 |
accuracy=0.956140350877193 f1_score=0.965034965034965 precision_score=0.9583333333333334 recall_score=0.971830985915493 |
Build, test and deploy Model serving functions#
MLRun serving can produce managed, real-time, serverless, pipelines composed of various data processing and ML tasks. The pipelines use the Nuclio real-time serverless engine, which can be deployed anywhere. For more details and examples, see the MLRun Serving Graphs.
Load the model serving function from our project
# serving_fn = mlrun.code_to_function("src/serving", filename="serving.py", image="mlrun/mlrun", kind="serving")
serving_fn = project.func('serving')
Adding a model to it:
serving_fn.add_model('cancer-classifier',model_path=hp_tuning_run.outputs["model"], class_name='ClassifierModel')
<mlrun.serving.states.TaskStep at 0x7f7c40199fd0>
# plot the serving graph topology
serving_fn.spec.graph.plot()

Simulating the model server locally:
# create a mock (simulator of the real-time function)
server = serving_fn.to_mock_server()
> 2022-08-24 09:00:59,960 [info] model cancer-classifier was loaded
> 2022-08-24 09:00:59,963 [info] Loaded ['cancer-classifier']
Test the mock model server endpoint:
List the served models
server.test("/v2/models/", method="GET")
{'models': ['cancer-classifier']}
Infer using test data
my_data = {
"inputs":[
[
1.371e+01, 2.083e+01, 9.020e+01, 5.779e+02, 1.189e-01, 1.645e-01,
9.366e-02, 5.985e-02, 2.196e-01, 7.451e-02, 5.835e-01, 1.377e+00,
3.856e+00, 5.096e+01, 8.805e-03, 3.029e-02, 2.488e-02, 1.448e-02,
1.486e-02, 5.412e-03, 1.706e+01, 2.814e+01, 1.106e+02, 8.970e+02,
1.654e-01, 3.682e-01, 2.678e-01, 1.556e-01, 3.196e-01, 1.151e-01
],
[
1.308e+01, 1.571e+01, 8.563e+01, 5.200e+02, 1.075e-01, 1.270e-01,
4.568e-02, 3.110e-02, 1.967e-01, 6.811e-02, 1.852e-01, 7.477e-01,
1.383e+00, 1.467e+01, 4.097e-03, 1.898e-02, 1.698e-02, 6.490e-03,
1.678e-02, 2.425e-03, 1.450e+01, 2.049e+01, 9.609e+01, 6.305e+02,
1.312e-01, 2.776e-01, 1.890e-01, 7.283e-02, 3.184e-01, 8.183e-02]
]
}
server.test("/v2/models/cancer-classifier/infer", body=my_data)
/opt/conda/lib/python3.8/site-packages/sklearn/base.py:450: UserWarning:
X does not have valid feature names, but GradientBoostingClassifier was fitted with feature names
{'id': '94009095fa4c4ec59217113909d2406b',
'model_name': 'cancer-classifier',
'outputs': [0, 1]}
Read the model name, ver and schema (input and output features)
server.test("/v2/models/cancer-classifier/", method="GET")
{'name': 'cancer-classifier',
'version': '',
'inputs': [{'name': 'mean radius', 'value_type': 'float'},
{'name': 'mean texture', 'value_type': 'float'},
{'name': 'mean perimeter', 'value_type': 'float'},
{'name': 'mean area', 'value_type': 'float'},
{'name': 'mean smoothness', 'value_type': 'float'},
{'name': 'mean compactness', 'value_type': 'float'},
{'name': 'mean concavity', 'value_type': 'float'},
{'name': 'mean concave points', 'value_type': 'float'},
{'name': 'mean symmetry', 'value_type': 'float'},
{'name': 'mean fractal dimension', 'value_type': 'float'},
{'name': 'radius error', 'value_type': 'float'},
{'name': 'texture error', 'value_type': 'float'},
{'name': 'perimeter error', 'value_type': 'float'},
{'name': 'area error', 'value_type': 'float'},
{'name': 'smoothness error', 'value_type': 'float'},
{'name': 'compactness error', 'value_type': 'float'},
{'name': 'concavity error', 'value_type': 'float'},
{'name': 'concave points error', 'value_type': 'float'},
{'name': 'symmetry error', 'value_type': 'float'},
{'name': 'fractal dimension error', 'value_type': 'float'},
{'name': 'worst radius', 'value_type': 'float'},
{'name': 'worst texture', 'value_type': 'float'},
{'name': 'worst perimeter', 'value_type': 'float'},
{'name': 'worst area', 'value_type': 'float'},
{'name': 'worst smoothness', 'value_type': 'float'},
{'name': 'worst compactness', 'value_type': 'float'},
{'name': 'worst concavity', 'value_type': 'float'},
{'name': 'worst concave points', 'value_type': 'float'},
{'name': 'worst symmetry', 'value_type': 'float'},
{'name': 'worst fractal dimension', 'value_type': 'float'}],
'outputs': [{'name': 'label', 'value_type': 'int'}]}
Deploy a real-time serving function (over Kubernetes or Docker):
Use the mlrun deploy_function() method to build and deploy a Nuclio serving function from your serving-function code.
You can deploy the function object (serving_fn) or reference pre-registered project functions.
This section requires Nuclio to be installed (over k8s or Docker) !
mlrun.deploy_function(serving_fn)
> 2022-08-24 09:01:00,021 [warning] it is recommended to use k8s secret (specify secret_name), specifying the aws_access_key/aws_secret_key directly is unsafe
> 2022-08-24 09:01:00,030 [info] Starting remote function deploy
2022-08-24 09:01:00 (info) Deploying function
2022-08-24 09:01:00 (info) Building
2022-08-24 09:01:00 (info) Staging files and preparing base images
2022-08-24 09:01:00 (info) Building processor image
2022-08-24 09:05:55 (info) Build complete
2022-08-24 09:06:19 (info) Function deploy complete
> 2022-08-24 09:06:20,612 [info] successfully deployed function: {'internal_invocation_urls': ['nuclio-breast-cancer-jovyan-serving.mlrun.svc.cluster.local:8080'], 'external_invocation_urls': ['localhost:30032']}
DeployStatus(state=ready, outputs={'endpoint': 'http://localhost:30032', 'name': 'breast-cancer-jovyan-serving'})
Test the live endpoint
serving_fn.invoke("/v2/models/cancer-classifier/infer", body=my_data)
> 2022-08-24 09:06:21,034 [info] invoking function: {'method': 'POST', 'path': 'http://nuclio-breast-cancer-jovyan-serving.mlrun.svc.cluster.local:8080/v2/models/cancer-classifier/infer'}
{'id': 'a1780a6c-173e-4649-a12b-4fbda92939b6',
'model_name': 'cancer-classifier',
'outputs': [0, 1]}
Build and run automated ML pipelines and CI/CD#
You can easily compose a workflow (see workflow.py from your functions that automatically prepares data, trains, tests, and deploys the model - every time you change the code or data, or need a refresh. See Project workflows and automation for details.
Using the SDK:
# run the workflow
run_id = project.run(
workflow_path="workflow.py",
arguments={"model_name": "breast_cancer_classifier"},
watch=True, local=no_k8s)

Run Results
Workflow bfc60bac-3a11-4c30-827d-bb74f49e87e7 finished, state=Succeededclick the hyper links below to see detailed results
| uid | start | state | name | parameters | results |
|---|---|---|---|---|---|
| Aug 24 09:07:07 | completed | trainer | accuracy=0.956140350877193 f1_score=0.965034965034965 precision_score=0.9583333333333334 recall_score=0.971830985915493 |
||
| Aug 24 09:06:39 | completed | get-data | format=pq model_name=breast_cancer_classifier |
label_column=label |
View the pipeline in MLRun UI:
Using the CLI:
With MLRun you can use a single command to load the code from local dir or remote archive (Git, zip, …) and execute a pipeline. This can be very useful for integration with CI/CD frameworks and practices. See Github/Gitlab and CI/CD integration for more details.
The following command loads the project from the current dir (.) and executes the workflow with an argument, for running locally (without k8s).
!mlrun project -r workflow.py -w -a model_name=classifier2 ./src
Loading project tutorial-jovyan into ./src:
kind: project
metadata:
name: tutorial-jovyan
spec:
functions:
- url: gen_breast_cancer.py
name: get-data
kind: job
image: mlrun/mlrun
handler: breast_cancer_generator
- url: trainer.py
name: trainer
image: mlrun/mlrun
handler: train
- url: serving.py
name: serving
kind: serving
image: mlrun/mlrun
workflows: []
artifacts: []
source: ''
desired_state: online
running workflow None file: workflow.py
> 2022-08-24 09:11:55,125 [warning] it is recommended to use k8s secret (specify secret_name), specifying the aws_access_key/aws_secret_key directly is unsafe
> 2022-08-24 09:11:55,128 [warning] it is recommended to use k8s secret (specify secret_name), specifying the aws_access_key/aws_secret_key directly is unsafe
> 2022-08-24 09:11:55,131 [warning] it is recommended to use k8s secret (specify secret_name), specifying the aws_access_key/aws_secret_key directly is unsafe
> 2022-08-24 09:11:55,627 [info] submitted pipeline tutorial-jovyan 2022-08-24 09-11-55 id=04c4557f-b33d-444d-bf59-a4d245888225
> 2022-08-24 09:11:55,628 [info] Pipeline run id=04c4557f-b33d-444d-bf59-a4d245888225, check UI for progress
Pipeline started in project tutorial-jovyan id=04c4557f-b33d-444d-bf59-a4d245888225, check progress in http://localhost:30060/projects/tutorial-jovyan/jobs/monitor-workflows/workflow/04c4557f-b33d-444d-bf59-a4d245888225
> 2022-08-24 09:11:55,629 [info] started run workflow tutorial-jovyan with run id = '04c4557f-b33d-444d-bf59-a4d245888225' by kfp engine
> 2022-08-24 09:11:55,629 [info] waiting for pipeline run completion
Workflow 04c4557f-b33d-444d-bf59-a4d245888225 finished, state=Succeeded
status name uid results
--------- -------- -------- -----------------------------------------------------------------------------------------------------------------------
completed trainer ..9934af accuracy=0.956140350877193,f1_score=0.965034965034965,precision_score=0.9583333333333334,recall_score=0.971830985915493
completed get-data ..8ec04c label_column=label
What’s Next - Check MLRun Docs and try:#
Use MLRun Feature-store to generate offline and real-time features from operational data
Track and retrain models with MLRun Model Monitoring