
Change log
Contents
Change log#
v1.3.0#
Client/server matrix, prerequisites, and installing#
The MLRun server is now based on Python 3.9. It’s recommended to move the client to Python 3.9 as well.
MLRun v1.3.0 maintains support for mlrun base images that are based on python 3.7. To differentiate between the images, the images based on
python 3.7 have the suffix: -py37. The correct version is automatically chosen for the built-in MLRun images according to the Python version of the MLRun client (for example, a 3.7 Jupyter gets the -py37 images).
MLRun is pre-installed in CE Jupyter.
To install on a Python 3.9 client, run:
./align_mlrun.sh
To install on a Python 3.7 client, run:
Configure the Jupyter service with the env variable
JUPYTER_PREFER_ENV_PATH=false.Within the Jupyter service, open a terminal and update conda and pip to have an up to date pip resolver.
$CONDA_HOME/bin/conda install -y pip
If you are going to work with python 3.9, create a new conda env and activate it:
conda create -n python39 python=3.9 ipykernel -y
conda activate python39
Install mlrun:
./align_mlrun.sh
New and updated features#
Feature store#
ID |
Description |
|---|---|
ML-2592 |
Offline data can be registered as feature sets (Tech Preview). See Create a feature set without ingesting its data. |
ML-2610 |
Supports SQLSource for batch ingestion (Tech Preview). See SQL data source. |
ML-2610 |
Supports SQLTarget for storey engine (Tech Preview). (Spark is not yet supported.) See SQL target store. |
ML-2709 |
The Spark engine now supports the steps: |
ML-2802 |
|
ML-2957 |
The username and password for the RedisNoSqlTarget are now configured using secrets, as |
ML-3008 |
Supports Spark using Redis as an online KV target, which caused a breaking change. |
ML-3373 |
Supports creating a feature vector over several feature sets with different entity. (Outer joins are Tech Preview.) See Using an offline feature vector. |
Logging data#
ID |
Description |
|---|---|
ML-2845 |
Logging data using |
Projects#
ID |
Description |
|---|---|
ML-3048 |
When defining a new project from scratch, there is now a default |
Serving graphs#
ID |
Description |
|---|---|
ML-1167 |
Add support for graphs that split and merge (DAG), including a list of steps for the |
ML-2507 |
Supports configuring of consumer group name for steps following QueueSteps. See Queue (streaming). |
Storey#
ID |
Description |
|---|---|
ML-2502 |
The event time in storey events is now taken from the |
UI#
ID |
Description |
|---|---|
ML-1186 |
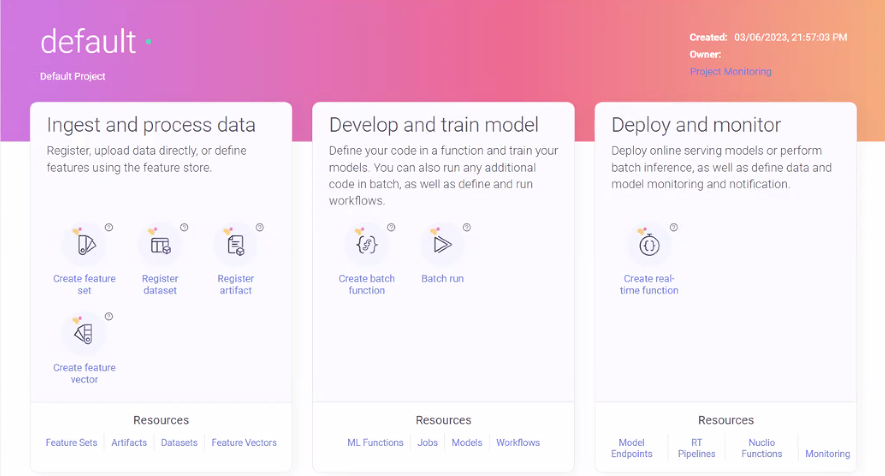
The new Projects home page provides easy and intuitive access to the full project lifecycle in three phases, with links to the relevant wizards under each phase heading: ingesting and processing data, developing and training a model, deploying and monitoring the project.
|
NA |
APIs#
ID |
Description |
|---|---|
ML-3104 |
These APIs now only return reasons in kwargs: |
ML-3204 |
New API |
Documentation#
Improvements to Set up your environment.
Infrastructure improvements#
ID |
Description |
|---|---|
ML-2609 |
MLRun server is based on Python 3.9. |
ML-2732 |
The new log collection service improves the performance and reduces heavy IO operations from the API container. The new MLRun log collector service is a gRPC server, which runs as sidecar in the mlrun-api pod (chief and worker). The service is responsible for collecting logs from run pods, writing to persisted files, and reading them on request. The new service is transparent to the end-user: there are no UI or API changes. |
Breaking changes#
The behavior of ingest with aggregation changed in v1.3.0 (storey, spark, pandas engines). Now, when you ingest a “timestamp” column, it returns
<class 'pandas._libs.tslibs.timestamps.Timestamp'>.
Previously, it returned<class 'str'>Any target data that was saved using Redis as an online target with storey engine (RedisNoSql target, introduced in 1.2.1) is not accessible after upgrading to v1.3. (Data ingested subsequent to the upgrade is unaffacted.)
Deprecated and removed APIs#
Starting with v1.3.0, and continuing in subsequent releases, obsolete functions are getting removed from the code.
Deprecated and removed from v1.3.0 code
These MLRun APIs have been deprecated since at least v1.0.0 and were removed from the code:
Deprecated/removed |
Use instead |
|---|---|
|
|
|
|
|
|
|
NA |
|
NA |
|
|
Feature-store: usage of state in graph. For example: |
|
|
|
|
|
Dask |
|
Dask |
|
Deprecated APIs, will be removed in v1.5.0
These APIs will be removed from the v1.5.0 code. A FutureWarning appears if you try to use them in v1.3.0.
Deprecated / to be removed |
Use instead |
|---|---|
project-related parameters of |
The same parameters in project-related APIs, such as |
|
|
Dask |
|
|
|
Spark runtime |
|
|
|
|
|
|
|
|
Add the function initialization to the pipeline code instead |
The entire |
|
|
|
REST APIs deprecated and removed from v1.3.0 code
pod_status headerfrom response toget_logREST APIclient-specfrom response to health APIsubmit_pipeline_legacyREST APIget_pipeline_legacyREST APIFive runtime legacy REST APIs, such as:
list_runtime_resources_legacy,delete_runtime_object_legacyetc.httpdb runtime-related APIs using the deprecated runtimes REST APIs, for example:
delete_runtime_object
Deprecated CLI#
The --ensure-project flag of the mlrun project CLI command is deprecated and will be removed in v1.5.0.
Closed issues#
ID |
Description |
|---|---|
ML-2421 |
Artifacts logged via SDK with “/” in the name can now be viewed in the UI. View in Git. |
ML-2534 |
Jobs and Workflows pages now display the tag of the executed job (as defined in the API). View in Git. |
ML-2810 |
Fixed the Dask Worker Memory Limit Argument. View in Git. |
ML-2896 |
|
ML-3104 |
Add support for project default image. View in Git. |
ML-3119 |
Fix: MPI job run status resolution considering all workers. View in Git. |
ML-3283 |
|
ML-3286 |
Fix: Project page displayed an empty list after an upgrade View in Git. |
ML-3316 |
Users with developer and data permissions can now add members to projects they created. (Previously appeared successful in the UI but users were not added). View in Git. |
ML-3365 / 3349 |
Fix: UI Projects’ metrics show N/A for all projects when ml-pipeline is down. View in Git. |
ML-3378 |
Aggregation over a fixed-window that starts at or near the epoch now functions as expected. View in Git. |
ML-3380 |
Documentation: added details on aggregation in windows. |
ML-3389 |
Hyperparams run does not present artifacts iteration when selector is not defined. View in Git. |
ML-3424 |
Documentation: new matrix of which engines support which sources/targets. View in Git. |
ML-3575 |
|
ML-3403 |
Error on Spark ingestion with offline target without defined path (error: |
ML-3446 |
Fix: Failed MLRun Nuclio deploy needs better error messages. View in Git. |
ML-3482 |
Fixed model-monitoring incompatibility issue with mlrun client running v1.1.x and a server running v1.2.x. View in Git. |
v1.2.1#
New and updated features#
Feature store#
Supports ingesting Avro-encoded Kafka records. View in Git.
Third party integrations#
Supports Confluent Kafka as a feature store data-source (Tech Preview). See Confluent Kafka data source.
Closed issues#
Fix: the Projects | Jobs | Monitor Workflows view is now accurate when filtering for > 1 hour. View in Git.
The Kubernetes Pods tab in Monitor Workflows now shows the complete pod details. View in Git.
Update the tooltips in Projects | Jobs | Schedule to explain that day 0 (for cron jobs) is Monday, and not Sunday. View in Git.
Fix UI crash when selecting All in the Tag dropdown list of the Projects | Feature Store | Feature Vectors tab. View in Git.
Fix: now updates
next_run_timewhen skipping scheduling due to concurrent runs. View in Git.When creating a project, the error
NotImplementedErrorwas updated to explain that MLRun does not have a DB to connect to. View in Git.When previewing a DirArtifact in the UI, it now returns the requested directory. Previously it was returning the directory list from the root of the container. View in Git.
Load source at runtime or build time now fully supports .zip files, which were not fully supported previously.
See more#
v1.2.0#
New and updated features#
Artifacts#
Support for artifact tagging:
SDK: Add
tag_artifactsanddelete_artifacts_tagsthat can be used to modify existing artifacts tags and have more than one version for an artifact.UI: You can add and edit artifact tags in the UI.
API: Introduce new endpoints in
/projects/<project>/tags.
Auth#
Support S3 profile and assume-role when using
fsspec.Support GitHub fine grained tokens.
Documentation#
Restructured, and added new content.
Feature store#
Support Redis as an online feature set for storey engine only. (See Redis target store.)
Fully supports ingesting with pandas engine, now equivalent to ingestion with
storeyengine (TechPreview):Support DataFrame with multi-index.
Support mlrun steps when using pandas engine:
OneHotEncoder,DateExtractor,MapValue,ImputerandFeatureValidation.
Add new step:
DropFeaturefor pandas and storey engines. (TechPreview)Add param query for
get_offline_featurefor filtering the output.
Frameworks#
Add
HuggingFaceModelServertomlrun.frameworksatmlrun.frameworks.huggingfaceto serveHuggingFacemodels.
Functions#
Add
function.with_annotations({"framework":"tensorflow"})to user-created functions.Add
overwrite_build_paramstoproject.build_function()so the user can choose whether or not to keep the build params that were used in previous function builds.deploy_functionhas a new option of mock deployment that allows running the function locally.
Installation#
New option to install
google-cloudrequirements usingmlrun[google-cloud]: when installing MLRun for integration with GCP clients, only compatible packages are installed.
Models#
The Labels in the Models > Overview tab can be edited.
Internal#
Refactor artifacts endpoints to follow the MLRun convention of
/projects/<project>/artifacts/.... (The previous API will be deprecated in a future release.)Add
/api/_internal/memory-reports/endpoints for memory related metrics to better understand the memory consumption of the API.Improve the HTTP retry mechanism.
Support a new lightweight mechanism for KFP pods to pull the run state they triggered. Default behavior is legacy, which pulls the logs of the run to figure out the run state. The new behavior can be enabled using a feature flag configured in the API.
Breaking changes#
Feature store: Ingestion using pandas now takes the dataframe and creates indices out of the entity column (and removes it as a column in this df). This could cause breakage for existing custom steps when using a pandas engine.
Closed issues#
Support logging artifacts larger than 5GB to V3IO. View in Git.
Limit KFP to kfp~=1.8.0, <1.8.14 due to non-backwards changes done in 1.8.14 for ParallelFor, which isn’t compatible with the MLRun managed KFP server (1.8.1). View in Git.
Add
artifact_pathenrichment from projectartifact_path. Previously, the parameter wasn’t applied to project runs when definingproject.artifact_path. View in Git.Align timeouts for requests that are getting re-routed from worker to chief (for projects/background related endpoints). View in Git.
Fix legacy artifacts load when loading a project. Fixed corner cases when legacy artifacts were saved to yaml and loaded back into the system using
load_project(). View in Git.Fix artifact
latesttag enrichment to happen also when user defined a specific tag. View in Git.Fix zip source extraction during function build. View in Git.
Fix Docker compose deployment so Nuclio is configured properly with a platformConfig file that sets proper mounts and network configuration for Nuclio functions, meaning that they run in the same network as MLRun. View in Git.
Workaround for background tasks getting cancelled prematurely, due to the current FastAPI version that has a bug in the starlette package it uses. The bug caused the task to get cancelled if the client’s HTTP connection was closed before the task was done. View in Git.
Fix run fails after deploying function without defined image. View in Git.
Fix scheduled jobs failed on GKE with resource quota error. View in Git.
Can now delete a model via tag. View in Git.
See more#
v1.1.3#
Closed issues#
The CLI supports overwriting the schedule when creating scheduling workflow. View in Git.
Slack now notifies when a project fails in
load_and_run(). View in Git.Timeout is executed properly when running a pipeline in CLI. View in Git.
Uvicorn Keep Alive Timeout (
http_connection_timeout_keep_alive) is now configurable, with default=11. This maintains API-client connections. View in Git.
See more#
v1.1.2#
New and updated features#
V3IO
v3io-py bumped to 0.5.19.
v3io-fs bumped to 0.1.15.
See more#
v1.1.1#
New and updated features#
API#
Supports workflow scheduling.
UI#
Projects: Supports editing model labels.
See more#
v1.1.0#
New and updated features#
API#
MLRun scalability: Workers are used to handle the connection to the MLRun database and can be increased to improve handling of high workloads against the MLRun DB. You can configure the number of workers for an MLRun service, which is applied to the service’s user-created pods. The default is 2.
v1.1.0 cannot run on top of 3.0.x.
For Iguazio versions prior to v3.5.0, the number of workers is set to 1 by default. To change this number, contact support (helm-chart change required).
Multi-instance is not supported for MLrun running on SQLite.
Supports pipeline scheduling.
Documentation#
Added Azure and S3 examples to Ingest features with Spark.
Feature store#
Supports S3, Azure, GCS targets when using Spark as an engine for the feature store.
Snowflake as datasource has a connector ID:
iguazio_platform.You can add a time-based filter condition when running
get_offline_featurewith a given vector.
Storey#
MLRun can write to parquet with flexible schema per batch for ParquetTarget: useful for inconsistent or unknown schema.
UI#
The Projects home page now has three tiles, Data, Jobs and Workflows, Deployment, that guide you through key capabilities of Iguazio, and provide quick access to common tasks.
The Projects | Jobs | Monitor Jobs tab now displays the Spark UI URL.
The information of the Drift Analysis tab is now displayed in the Model Overview.
If there is an error, the error messages are now displayed in the Projects | Jobs | Monitor jobs tab.
Workflows#
The steps in Workflows are color-coded to identify their status: blue=running; green=completed; red=error.
See more#
v1.0.6#
Closed issues#
Import from mlrun fails with “ImportError: cannot import name dataclass_transform”. Workaround for previous releases: Install
pip install pydantic==1.9.2afteralign_mlrun.sh.MLRun FeatureSet was not enriching with security context when running from the UI. View in Git.
MlRun Accesskey presents as cleartext in the mlrun yaml, when the mlrun function is created by feature set request from the UI. View in Git.
See more#
v1.0.5#
Closed issues#
MLRun: remove root permissions. View in Git.
Users running a pipeline via CLI project run (watch=true) can now set the timeout (previously was 1 hour). View in Git.
MLRun: Supports pushing images to ECR. View in Git.
See more#
v1.0.4#
New and updated features#
Bump storey to 1.0.6.
Add typing-extensions explicitly.
Add vulnerability check to CI and fix vulnerabilities.
Closed issues#
Limit Azure transitive dependency to avoid new bug. View in Git.
Fix GPU image to have new signing keys. View in Git.
Spark: Allow mounting v3io on driver but not executors. View in Git.
Tests: Send only string headers to align to new requests limitation. View in Git.
See more#
v1.0.3#
New and updated features#
Jupyter Image: Relax
artifact_pathsettings and add README notebook. View in Git.Images: Fix security vulnerabilities. View in Git.
Closed issues#
API: Fix projects leader to sync enrichment to followers. View in Git.
Projects: Fixes and usability improvements for working with archives. View in Git.
See more#
v1.0.2#
New and updated features#
Runtimes: Add java options to Spark job parameters. View in Git.
Spark: Allow setting executor and driver core parameter in Spark operator. View in Git.
API: Block unauthorized paths on files endpoints. View in Git.
Documentation: New quick start guide and updated docker install section. View in Git.
Closed issues#
Frameworks: Fix to logging the target columns in favor of model monitoring. View in Git.
Projects: Fix/support archives with project run/build/deploy methods. View in Git.
Runtimes: Fix jobs stuck in non-terminal state after node drain/pre-emption. View in Git.
Requirements: Fix ImportError on ingest to Azure. View in Git.
See more#
v1.0.0#
New and updated features#
Feature store#
Supports snowflake as a datasource for the feature store.
Graph#
A new tab under Projects | Models named Real-time pipelines displays the real time pipeline graph, with a drill-down to view the steps and their details. [Tech Preview]
Projects#
Setting owner and members are in a dedicated Project Settings section.
The Project Monitoring report has a new tile named Consumer groups (v3io streams) that shows the total number of consumer groups, with drill-down capabilities for more details.
Resource management#
Supports preemptible nodes.
Supports configuring CPU, GPU, and memory default limits for user jobs.
UI#
Supports configuring pod priority.
Enhanced masking of sensitive data.
The dataset tab is now in the Projects main menu (was previously under the Feature store).
See more#
Open issues#
ID |
Description |
Workaround |
Opened in |
|---|---|---|---|
ML-1584 |
Cannot run |
Do not use special characters in filenames |
v1.0.0 |
ML-2199 |
Spark operator job fails with default requests args. |
NA |
v1.0.0 |
ML-2223 |
Cannot deploy a function when notebook names contain “.” (ModuleNotFoundError) |
Do not use “.” in notebook name |
v1.0.0 |
ML-2407 |
Kafka ingestion service on an empty feature set returns an error. |
Ingest a sample of the data manually. This creates the schema for the feature set and then the ingestion service accepts new records. |
v1.1.0 |
ML-2489 |
Cannot pickle a class inside an mlrun function. |
Use cloudpickle instead of pickle |
v1.2.0 |
Running a workflow whose project has |
Run |
v1.1.0 |
|
ML-3386 |
Documentation is missing full details on the feature store sources and targets |
NA |
v1.2.1 |
ML-3420 |
MLRun database doesn’t raise an exception when the blob size is greater than 16,777,215 bytes |
NA |
v1.2.1 |
ML-3445 |
|
Replace code: |
v1.3.0 |
ML-3480 |
Documentation: request details on label parameter of feature set definition |
NA |
v1.2.1 |
NA |
The feature store does not support schema evolution and does not have schema enforcement. |
NA |
v1.2.1 |
ML-3633 |
Fail to import a context from dict |
When loading a context from dict (e.g.: mlrun.MLClientCtx.from_dict(context)), make sure to provide datetime objects and not string. Do this by executing |
v1.3.0 |
ML-3640 |
When running a remote function/workflow, the |
Use |
1.3.0 |
Limitations#
ID |
Description |
Workaround |
Opened in |
|---|---|---|---|
ML-2014 |
Model deployment returns ResourceNotFoundException (Nuclio error that Service |
Verify that all |
v1.0.0 |
ML-3315 |
The feature store does not support an aggregation of aggregations |
NA |
v1.2.1 |
ML-3381 |
Private repo is not supported as a marketplace hub |
NA |
v1.2.1 |
Deprecations#
In |
ID |
Description |
|---|---|---|
v1.0.0 |
MLRun / Nuclio do not support python 3.6. |
|
v1.3.0 |
See Deprecated APIs. |