
Hyperparameter tuning optimization
Contents
Hyperparameter tuning optimization#
MLRun supports iterative tasks for automatic and distributed execution of many tasks with variable parameters (hyperparams). Iterative tasks can be distributed across multiple containers. They can be used for:
Parallel loading and preparation of many data objects
Model training with different parameter sets and/or algorithms
Parallel testing with many test vector options
AutoML
MLRun iterations can be viewed as child runs under the main task/run. Each child run gets a set of parameters that are computed/selected from the input hyperparameters based on the chosen strategy (Grid, List, Random or Custom).
The different iterations can run in parallel over multiple containers (using Dask or Nuclio runtimes, which manage the workers). Read more in Parallel execution over containers.
The hyperparameters and options are specified in the task or the run() command
through the hyperparams (for hyperparam values) and hyper_param_options (for
HyperParamOptions) properties. See the examples below. Hyperparameters can also be loaded directly
from a CSV or Json file (by setting the param_file hyper option).
The hyperparams are specified as a struct of key: list values for example: {"p1": [1,2,3], "p2": [10,20]}. The values
can be of any type (int, string, float, …). The lists are used to compute the parameter combinations using one of the
following strategies:
Grid search (
grid) — running all the parameter combinations.Random (
random) — running a sampled set from all the parameter combinations.List (
list) — running the first parameter from each list followed by the seco2nd from each list and so on. All the lists must be of equal size.Custom (
custom) — determine the parameter combination per run programmatically.
You can specify a selection criteria to select the best run among the different child runs by setting the selector option. This marks the selected result as the parent (iteration 0) result, and marks the best result in the user interface.
You can also specify the stop_condition to stop the execution of child runs when some criteria, based on the returned results, is met (for example stop_condition="accuracy>=0.9").
In this section
Basic code#
Here’s a basic example of running multiple jobs in parallel for hyperparameters tuning, selecting the best run with respect to the max accuracy.
Run the hyperparameters tuning job by using the keywords arguments:
hyperparamsfor the hyperparameters options and values of choice.selectorfor specifying how to select the best model.
hp_tuning_run = project.run_function(
"trainer",
inputs={"dataset": gen_data_run.outputs["dataset"]},
hyperparams={
"n_estimators": [100, 500, 1000],
"max_depth": [5, 15, 30]
},
selector="max.accuracy",
local=True
)
The returned run object in this case represents the parent (and the best result). You can also access the
individual child runs (called iterations) in the MLRun UI.
Review the results#
When running a hyperparam job, the job results tab shows the list and marks the best run:
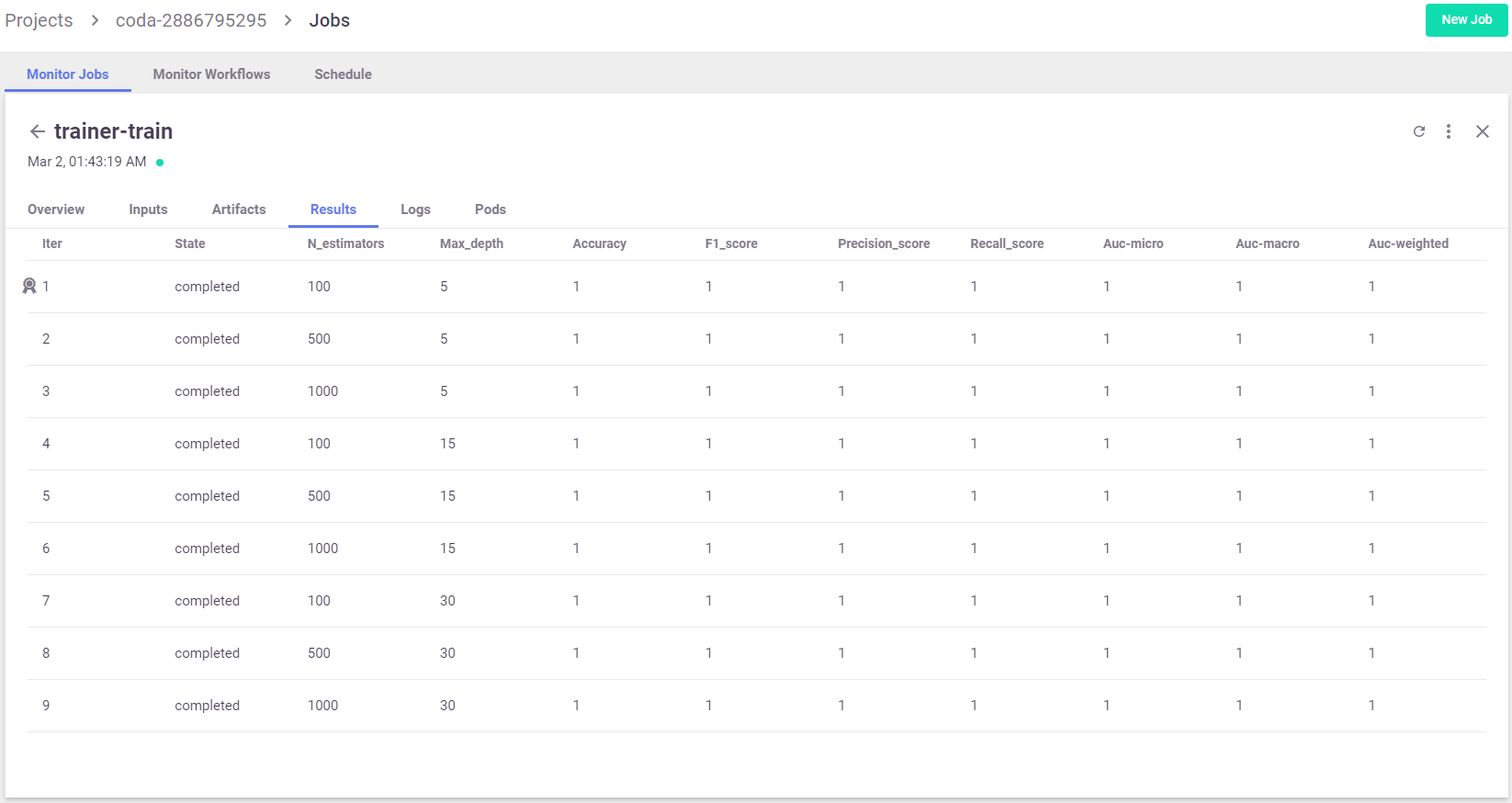
You can also view results by printing the artifact iteration_results:
hp_tuning_run.artifact("iteration_results").as_df()
MLRun also generates a parallel coordinates plot for the run, you can view it in the MLRun UI.
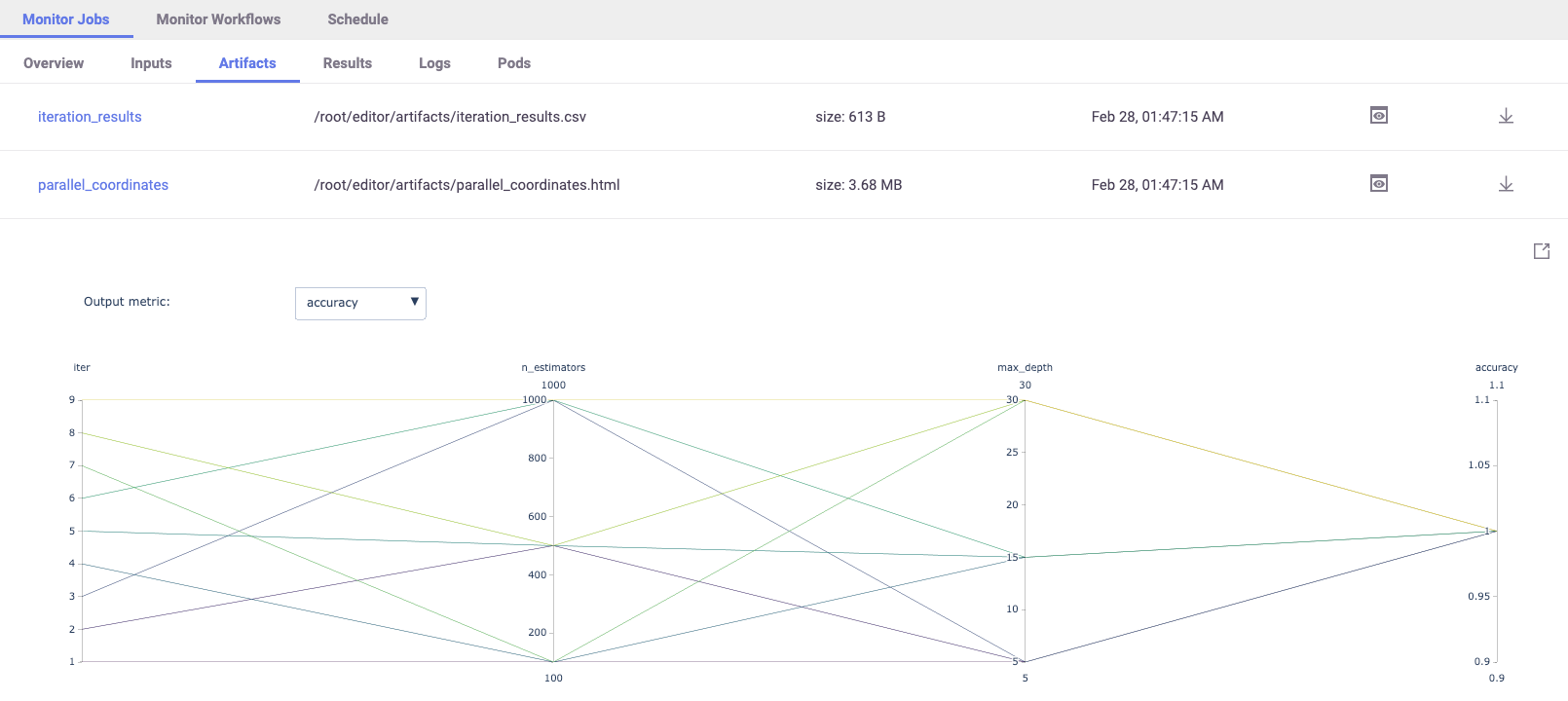
Examples#
Base dummy function:
import mlrun
> 2021-10-23 12:47:39,982 [warning] Failed resolving version info. Ignoring and using defaults
> 2021-10-23 12:47:43,488 [warning] Unable to parse server or client version. Assuming compatible: {'server_version': '0.8.0-rc7', 'client_version': 'unstable'}
def hyper_func(context, p1, p2):
print(f"p1={p1}, p2={p2}, result={p1 * p2}")
context.log_result("multiplier", p1 * p2)
Grid search (default)#
grid_params = {"p1": [2,4,1], "p2": [10,20]}
task = mlrun.new_task("grid-demo").with_hyper_params(grid_params, selector="max.multiplier")
run = mlrun.new_function().run(task, handler=hyper_func)
> 2021-10-23 12:47:43,505 [info] starting run grid-demo uid=29c9083db6774e5096a97c9b6b6c8e93 DB=http://mlrun-api:8080
p1=2, p2=10, result=20
p1=4, p2=10, result=40
p1=1, p2=10, result=10
p1=2, p2=20, result=40
p1=4, p2=20, result=80
p1=1, p2=20, result=20
> 2021-10-23 12:47:44,851 [info] best iteration=5, used criteria max.multiplier
| project | uid | iter | start | state | name | labels | inputs | parameters | results | artifacts |
|---|---|---|---|---|---|---|---|---|---|---|
| default | 0 | Oct 23 12:47:43 | completed | grid-demo | v3io_user=admin kind=handler owner=admin |
best_iteration=5 multiplier=80 |
iteration_results |
> 2021-10-23 12:47:45,071 [info] run executed, status=completed
UI Screenshot:
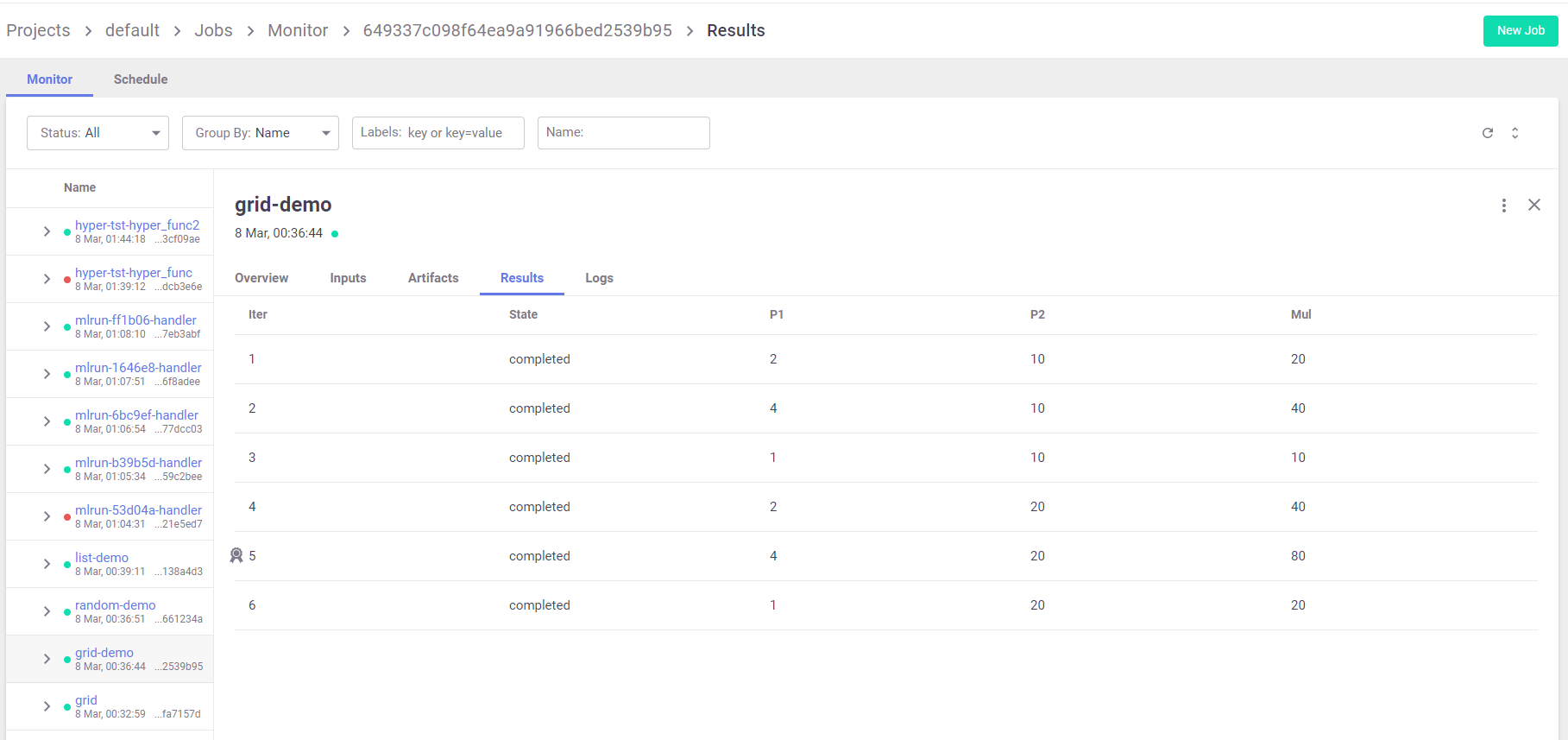
Random Search#
MLRun chooses random parameter combinations. Limit the number of combinations using the max_iterations attribute.
grid_params = {"p1": [2,4,1,3], "p2": [10,20,30]}
task = mlrun.new_task("random-demo")
task.with_hyper_params(grid_params, selector="max.multiplier", strategy="random", max_iterations=4)
run = mlrun.new_function().run(task, handler=hyper_func)
> 2021-10-23 12:47:45,077 [info] starting run random-demo uid=cac368c7fc33455f97ca806e5c7abf2f DB=http://mlrun-api:8080
p1=2, p2=20, result=40
p1=4, p2=10, result=40
p1=3, p2=10, result=30
p1=3, p2=20, result=60
> 2021-10-23 12:47:45,966 [info] best iteration=4, used criteria max.multiplier
| project | uid | iter | start | state | name | labels | inputs | parameters | results | artifacts |
|---|---|---|---|---|---|---|---|---|---|---|
| default | 0 | Oct 23 12:47:45 | completed | random-demo | v3io_user=admin kind=handler owner=admin |
best_iteration=4 multiplier=60 |
iteration_results |
> 2021-10-23 12:47:46,177 [info] run executed, status=completed
List search#
This example also shows how to use the stop_condition option.
list_params = {"p1": [2,3,7,4,5], "p2": [15,10,10,20,30]}
task = mlrun.new_task("list-demo").with_hyper_params(
list_params, selector="max.multiplier", strategy="list", stop_condition="multiplier>=70")
run = mlrun.new_function().run(task, handler=hyper_func)
> 2021-10-23 12:47:46,184 [info] starting run list-demo uid=136edfb9c9404a61933c73bbbd35b18b DB=http://mlrun-api:8080
p1=2, p2=15, result=30
p1=3, p2=10, result=30
p1=7, p2=10, result=70
> 2021-10-23 12:47:47,193 [info] reached early stop condition (multiplier>=70), stopping iterations!
> 2021-10-23 12:47:47,195 [info] best iteration=3, used criteria max.multiplier
| project | uid | iter | start | state | name | labels | inputs | parameters | results | artifacts |
|---|---|---|---|---|---|---|---|---|---|---|
| default | 0 | Oct 23 12:47:46 | completed | list-demo | v3io_user=admin kind=handler owner=admin |
best_iteration=3 multiplier=70 |
iteration_results |
> 2021-10-23 12:47:47,385 [info] run executed, status=completed
Custom iterator#
You can define a child iteration context under the parent/main run. The child run is logged independently.
def handler(context: mlrun.MLClientCtx, param_list):
best_multiplier = total = 0
for param in param_list:
with context.get_child_context(**param) as child:
hyper_func(child, **child.parameters)
multiplier = child.results['multiplier']
total += multiplier
if multiplier > best_multiplier:
child.mark_as_best()
best_multiplier = multiplier
# log result at the parent
context.log_result('avg_multiplier', total / len(param_list))
param_list = [{"p1":2, "p2":10}, {"p1":3, "p2":30}, {"p1":4, "p2":7}]
run = mlrun.new_function().run(handler=handler, params={"param_list": param_list})
> 2021-10-23 12:47:47,403 [info] starting run mlrun-a79c5c-handler uid=c3eb08ebae02464ca4025c77b12e3c39 DB=http://mlrun-api:8080
p1=2, p2=10, result=20
p1=3, p2=30, result=90
p1=4, p2=7, result=28
| project | uid | iter | start | state | name | labels | inputs | parameters | results | artifacts |
|---|---|---|---|---|---|---|---|---|---|---|
| default | 0 | Oct 23 12:47:47 | completed | mlrun-a79c5c-handler | v3io_user=admin kind=handler owner=admin host=jupyter-6476bb5f85-bjc4m |
param_list=[{'p1': 2, 'p2': 10}, {'p1': 3, 'p2': 30}, {'p1': 4, 'p2': 7}] |
best_iteration=2 multiplier=90 avg_multiplier=46.0 |
> 2021-10-23 12:47:48,734 [info] run executed, status=completed
Parallel execution over containers#
When working with compute intensive or long running tasks you’ll want to run your iterations over a cluster of containers. At the same time, you don’t want to bring up too many containers, and you want to limit the number of parallel tasks.
MLRun supports distribution of the child runs over Dask or Nuclio clusters. This is handled automatically by MLRun. You only need to deploy the Dask or Nuclio function used by the workers, and set the level of parallelism in the task. The execution can be controlled from the client/notebook, or can have a job (immediate or scheduled) that controls the execution.
Code example (single task)#
# mark the start of a code section that will be sent to the job
# mlrun: start-code
import socket
import pandas as pd
def hyper_func2(context, data, p1, p2, p3):
print(data.as_df().head())
context.logger.info(f"p2={p2}, p3={p3}, r1={p2 * p3} at {socket.gethostname()}")
context.log_result("r1", p2 * p3)
raw_data = {
"first_name": ["Jason", "Molly", "Tina", "Jake", "Amy"],
"age": [42, 52, 36, 24, 73],
"testScore": [25, 94, 57, 62, 70],
}
df = pd.DataFrame(raw_data, columns=["first_name", "age", "testScore"])
context.log_dataset("mydf", df=df, stats=True)
# mlrun: end-code
Running the workers using Dask#
This example creates a new function and executes the parent/controller as an MLRun job and the different child runs over a Dask cluster (MLRun Dask function).
Define a Dask cluster (using MLRun serverless Dask)#
dask_cluster = mlrun.new_function("dask-cluster", kind='dask', image='mlrun/ml-models')
dask_cluster.apply(mlrun.mount_v3io()) # add volume mounts
dask_cluster.spec.service_type = "NodePort" # open interface to the dask UI dashboard
dask_cluster.spec.replicas = 2 # define two containers
uri = dask_cluster.save()
uri
'db://default/dask-cluster'
# initialize the dask cluster and get its dashboard url
dask_cluster.client
> 2021-10-23 12:48:49,020 [info] trying dask client at: tcp://mlrun-dask-cluster-eea516ff-5.default-tenant:8786
> 2021-10-23 12:48:49,049 [info] using remote dask scheduler (mlrun-dask-cluster-eea516ff-5) at: tcp://mlrun-dask-cluster-eea516ff-5.default-tenant:8786
Mismatched versions found
+-------------+--------+-----------+---------+
| Package | client | scheduler | workers |
+-------------+--------+-----------+---------+
| blosc | 1.7.0 | 1.10.6 | None |
| cloudpickle | 1.6.0 | 2.0.0 | None |
| distributed | 2.30.0 | 2.30.1 | None |
| lz4 | 3.1.0 | 3.1.3 | None |
| msgpack | 1.0.0 | 1.0.2 | None |
| tornado | 6.0.4 | 6.1 | None |
+-------------+--------+-----------+---------+
Notes:
- msgpack: Variation is ok, as long as everything is above 0.6
Client
|
Cluster
|
Define the parallel work#
Set the parallel_runs attribute to indicate how many child tasks to run in parallel. Set the dask_cluster_uri to point
to the dask cluster (if it’s not set the cluster uri uses dask local). You can also set the teardown_dask flag to free up
all the dask resources after completion.
grid_params = {"p2": [2,1,4,1], "p3": [10,20]}
task = mlrun.new_task(params={"p1": 8}, inputs={'data': 'https://s3.wasabisys.com/iguazio/data/iris/iris_dataset.csv'})
task.with_hyper_params(
grid_params, selector="r1", strategy="grid", parallel_runs=4, dask_cluster_uri=uri, teardown_dask=True
)
<mlrun.model.RunTemplate at 0x7f673d7b1910>
Define a job that will take the code (using code_to_function) and run it over the cluster
fn = mlrun.code_to_function(name='hyper-tst', kind='job', image='mlrun/ml-models')
run = fn.run(task, handler=hyper_func2)
> 2021-10-23 12:49:56,388 [info] starting run hyper-tst-hyper_func2 uid=50eb72f5b0734954b8b1c57494f325bc DB=http://mlrun-api:8080
> 2021-10-23 12:49:56,565 [info] Job is running in the background, pod: hyper-tst-hyper-func2-9g6z8
> 2021-10-23 12:49:59,813 [info] trying dask client at: tcp://mlrun-dask-cluster-eea516ff-5.default-tenant:8786
> 2021-10-23 12:50:09,828 [warning] remote scheduler at tcp://mlrun-dask-cluster-eea516ff-5.default-tenant:8786 not ready, will try to restart Timed out trying to connect to tcp://mlrun-dask-cluster-eea516ff-5.default-tenant:8786 after 10 s
> 2021-10-23 12:50:15,733 [info] using remote dask scheduler (mlrun-dask-cluster-04574796-5) at: tcp://mlrun-dask-cluster-04574796-5.default-tenant:8786
remote dashboard: default-tenant.app.yh38.iguazio-cd2.com:32577
> --------------- Iteration: (1) ---------------
sepal length (cm) sepal width (cm) ... petal width (cm) label
0 5.1 3.5 ... 0.2 0
1 4.9 3.0 ... 0.2 0
2 4.7 3.2 ... 0.2 0
3 4.6 3.1 ... 0.2 0
4 5.0 3.6 ... 0.2 0
[5 rows x 5 columns]
> 2021-10-23 12:50:21,353 [info] p2=2, p3=10, r1=20 at mlrun-dask-cluster-04574796-5k5lhq
> --------------- Iteration: (3) ---------------
sepal length (cm) sepal width (cm) ... petal width (cm) label
0 5.1 3.5 ... 0.2 0
1 4.9 3.0 ... 0.2 0
2 4.7 3.2 ... 0.2 0
3 4.6 3.1 ... 0.2 0
4 5.0 3.6 ... 0.2 0
[5 rows x 5 columns]
> 2021-10-23 12:50:21,459 [info] p2=4, p3=10, r1=40 at mlrun-dask-cluster-04574796-5k5lhq
> --------------- Iteration: (4) ---------------
sepal length (cm) sepal width (cm) ... petal width (cm) label
0 5.1 3.5 ... 0.2 0
1 4.9 3.0 ... 0.2 0
2 4.7 3.2 ... 0.2 0
3 4.6 3.1 ... 0.2 0
4 5.0 3.6 ... 0.2 0
[5 rows x 5 columns]
> 2021-10-23 12:50:21,542 [info] p2=1, p3=10, r1=10 at mlrun-dask-cluster-04574796-5k5lhq
> --------------- Iteration: (6) ---------------
sepal length (cm) sepal width (cm) ... petal width (cm) label
0 5.1 3.5 ... 0.2 0
1 4.9 3.0 ... 0.2 0
2 4.7 3.2 ... 0.2 0
3 4.6 3.1 ... 0.2 0
4 5.0 3.6 ... 0.2 0
[5 rows x 5 columns]
> 2021-10-23 12:50:21,629 [info] p2=1, p3=20, r1=20 at mlrun-dask-cluster-04574796-5k5lhq
> --------------- Iteration: (7) ---------------
sepal length (cm) sepal width (cm) ... petal width (cm) label
0 5.1 3.5 ... 0.2 0
1 4.9 3.0 ... 0.2 0
2 4.7 3.2 ... 0.2 0
3 4.6 3.1 ... 0.2 0
4 5.0 3.6 ... 0.2 0
[5 rows x 5 columns]
> 2021-10-23 12:50:21,792 [info] p2=4, p3=20, r1=80 at mlrun-dask-cluster-04574796-5k5lhq
> --------------- Iteration: (8) ---------------
sepal length (cm) sepal width (cm) ... petal width (cm) label
0 5.1 3.5 ... 0.2 0
1 4.9 3.0 ... 0.2 0
2 4.7 3.2 ... 0.2 0
3 4.6 3.1 ... 0.2 0
4 5.0 3.6 ... 0.2 0
[5 rows x 5 columns]
> 2021-10-23 12:50:22,052 [info] p2=1, p3=20, r1=20 at mlrun-dask-cluster-04574796-5k5lhq
> --------------- Iteration: (2) ---------------
sepal length (cm) sepal width (cm) ... petal width (cm) label
0 5.1 3.5 ... 0.2 0
1 4.9 3.0 ... 0.2 0
2 4.7 3.2 ... 0.2 0
3 4.6 3.1 ... 0.2 0
4 5.0 3.6 ... 0.2 0
[5 rows x 5 columns]
> 2021-10-23 12:50:23,134 [info] p2=1, p3=10, r1=10 at mlrun-dask-cluster-04574796-5j6v59
> --------------- Iteration: (5) ---------------
sepal length (cm) sepal width (cm) ... petal width (cm) label
0 5.1 3.5 ... 0.2 0
1 4.9 3.0 ... 0.2 0
2 4.7 3.2 ... 0.2 0
3 4.6 3.1 ... 0.2 0
4 5.0 3.6 ... 0.2 0
[5 rows x 5 columns]
> 2021-10-23 12:50:23,219 [info] p2=2, p3=20, r1=40 at mlrun-dask-cluster-04574796-5k5lhq
> 2021-10-23 12:50:23,261 [info] tearing down the dask cluster..
> 2021-10-23 12:50:43,363 [info] best iteration=7, used criteria r1
> 2021-10-23 12:50:43,626 [info] run executed, status=completed
final state: completed
| project | uid | iter | start | state | name | labels | inputs | parameters | results | artifacts |
|---|---|---|---|---|---|---|---|---|---|---|
| default | 0 | Oct 23 12:49:59 | completed | hyper-tst-hyper_func2 | v3io_user=admin kind=job owner=admin |
data |
p1=8 |
best_iteration=7 r1=80 |
mydf iteration_results |
> 2021-10-23 12:50:53,303 [info] run executed, status=completed
Running the workers using Nuclio#
Nuclio is a high-performance serverless engine that can process many events in parallel. It can also separate initialization from execution. Certain parts of the code (imports, loading data, etc.) can be done once per worker vs. in any run.
Nuclio, by default, process events (http, stream, …). There is a special Nuclio kind that runs MLRun jobs (nuclio:mlrun).
Notes
Nuclio tasks are relatively short (preferably under 5 minutes), use it for running many iterations where each individual run is less than 5 min.
Use
context.loggerto drive text outputs (vsprint()).
Create a nuclio:mlrun function#
fn = mlrun.code_to_function(name='hyper-tst2', kind='nuclio:mlrun', image='mlrun/mlrun')
# replicas * workers need to match or exceed parallel_runs
fn.spec.replicas = 2
fn.with_http(workers=2)
fn.deploy()
> 2021-10-23 12:51:10,152 [info] Starting remote function deploy
2021-10-23 12:51:10 (info) Deploying function
2021-10-23 12:51:10 (info) Building
2021-10-23 12:51:10 (info) Staging files and preparing base images
2021-10-23 12:51:10 (info) Building processor image
2021-10-23 12:51:11 (info) Build complete
2021-10-23 12:51:19 (info) Function deploy complete
> 2021-10-23 12:51:22,296 [info] successfully deployed function: {'internal_invocation_urls': ['nuclio-default-hyper-tst2.default-tenant.svc.cluster.local:8080'], 'external_invocation_urls': ['default-tenant.app.yh38.iguazio-cd2.com:32760']}
'http://default-tenant.app.yh38.iguazio-cd2.com:32760'
Run the parallel task over the function#
# this is required to fix Jupyter issue with asyncio (not required outside of Jupyter)
# run it only once
import nest_asyncio
nest_asyncio.apply()
grid_params = {"p2": [2,1,4,1], "p3": [10,20]}
task = mlrun.new_task(params={"p1": 8}, inputs={'data': 'https://s3.wasabisys.com/iguazio/data/iris/iris_dataset.csv'})
task.with_hyper_params(
grid_params, selector="r1", strategy="grid", parallel_runs=4, max_errors=3
)
run = fn.run(task, handler=hyper_func2)
> 2021-10-23 12:51:31,618 [info] starting run hyper-tst2-hyper_func2 uid=97cc3e255f3c4c93822b0154d63f47f5 DB=http://mlrun-api:8080
> --------------- Iteration: (4) ---------------
2021-10-23 12:51:32.130812 info logging run results to: http://mlrun-api:8080 worker_id=1
2021-10-23 12:51:32.401258 info p2=1, p3=10, r1=10 at nuclio-default-hyper-tst2-5d4976b685-47dh6 worker_id=1
> --------------- Iteration: (2) ---------------
2021-10-23 12:51:32.130713 info logging run results to: http://mlrun-api:8080 worker_id=0
2021-10-23 12:51:32.409468 info p2=1, p3=10, r1=10 at nuclio-default-hyper-tst2-5d4976b685-47dh6 worker_id=0
> --------------- Iteration: (1) ---------------
2021-10-23 12:51:32.130765 info logging run results to: http://mlrun-api:8080 worker_id=0
2021-10-23 12:51:32.432121 info p2=2, p3=10, r1=20 at nuclio-default-hyper-tst2-5d4976b685-2gdtc worker_id=0
> --------------- Iteration: (5) ---------------
2021-10-23 12:51:32.568848 info logging run results to: http://mlrun-api:8080 worker_id=0
2021-10-23 12:51:32.716415 info p2=2, p3=20, r1=40 at nuclio-default-hyper-tst2-5d4976b685-47dh6 worker_id=0
> --------------- Iteration: (7) ---------------
2021-10-23 12:51:32.855399 info logging run results to: http://mlrun-api:8080 worker_id=1
2021-10-23 12:51:33.054417 info p2=4, p3=20, r1=80 at nuclio-default-hyper-tst2-5d4976b685-2gdtc worker_id=1
> --------------- Iteration: (6) ---------------
2021-10-23 12:51:32.970002 info logging run results to: http://mlrun-api:8080 worker_id=0
2021-10-23 12:51:33.136621 info p2=1, p3=20, r1=20 at nuclio-default-hyper-tst2-5d4976b685-47dh6 worker_id=0
> --------------- Iteration: (3) ---------------
2021-10-23 12:51:32.541187 info logging run results to: http://mlrun-api:8080 worker_id=1
2021-10-23 12:51:33.301200 info p2=4, p3=10, r1=40 at nuclio-default-hyper-tst2-5d4976b685-47dh6 worker_id=1
> --------------- Iteration: (8) ---------------
2021-10-23 12:51:33.419442 info logging run results to: http://mlrun-api:8080 worker_id=0
2021-10-23 12:51:33.672165 info p2=1, p3=20, r1=20 at nuclio-default-hyper-tst2-5d4976b685-47dh6 worker_id=0
> 2021-10-23 12:51:34,153 [info] best iteration=7, used criteria r1
| project | uid | iter | start | state | name | labels | inputs | parameters | results | artifacts |
|---|---|---|---|---|---|---|---|---|---|---|
| default | 0 | Oct 23 12:51:31 | completed | hyper-tst2-hyper_func2 | v3io_user=admin kind=remote owner=admin |
data |
p1=8 |
best_iteration=7 r1=80 |
mydf iteration_results |
> 2021-10-23 12:51:34,420 [info] run executed, status=completed