
What is MLRun? ¶
The challenge¶
As an ML developer or data scientist, you typically want to write code in your preferred local development environment (IDE) or web notebook, and then run the same code on a larger cluster using scale-out containers or functions. When you determine that the code is ready, you or someone else needs to transfer the code to an automated ML workflow (for example, using Kubeflow Pipelines). This pipeline should be secure and include capabilities such as logging and monitoring, as well as allow adjustments to relevant components and easy redeployment.
After you develop your model and feature engineering logic you need to deploy those into production pipelines with real-time feature engineering, online model serving, API and data integrations, model and data quality monitoring, no intrusive upgrades and so on.
However, the implementation is challenging: various environments (“runtimes”) use different configurations, parameters, and data sources. In addition, multiple frameworks and platforms are used to focus on different stages of the development life cycle. This leads to constant development and DevOps/MLOps work.
Furthermore, as your project scales, you need greater computation power or GPUs, and you need to access large-scale data sets. This cannot succeed on laptops. You need a way to seamlessly run your code on a remote cluster and automatically scale it out.
Why MLRun?¶
When running ML experiments, ideally you can record and version your code, configuration, outputs, and associated inputs (lineage), so you can easily reproduce and explain your results. The fact that you probably need to use different types of storage (such as files and AWS S3 buckets) and various databases, further complicates the implementation.
Once the development is complete, it’s time to serve models online or build real-time pipelines without having to refactor or re-implement the logic, or call in an army of developers to help.
Wouldn’t it be great if you could write the code once, using your preferred development environment and simple “local” semantics, and then run it as-is on different platforms? Imagine having a layer that automates the build process, execution, data movement, scaling, versioning, parameterization, outputs tracking, deployment to production, monitoring, and more. A world of easily developed, published, or consumed data or ML “functions” that can be used to form complex and large-scale offline or real-time ML pipelines.
In addition, imagine a marketplace of ML functions that includes both open-source templates and your internally developed functions, to support code for reuse across projects and companies and thus further accelerate your work.
That is what MLRun does — simplifies & accelerates the time to production.
Architecture¶
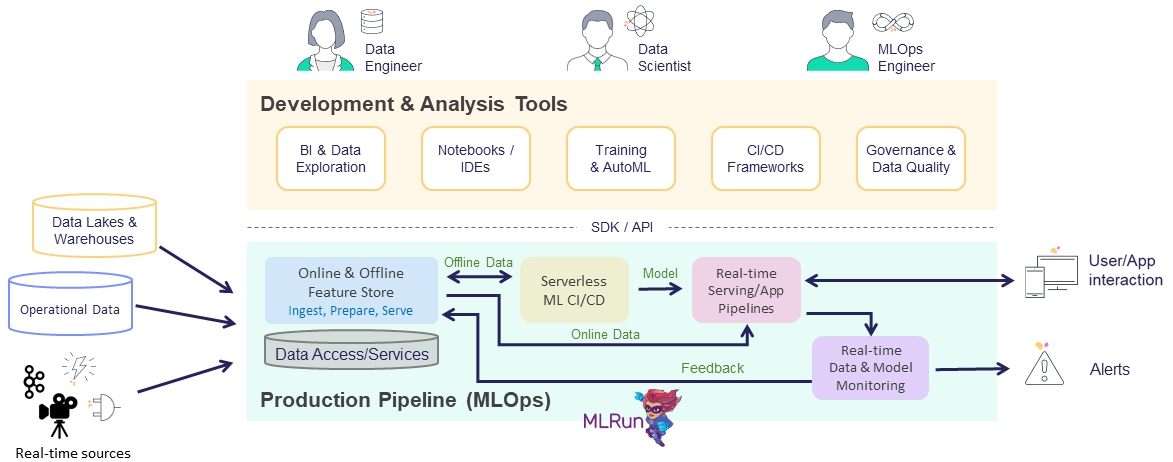
MLRun is composed of the following layers:
Feature Store — collects, prepares, catalogs, and serves data features for development (offline) and real-time (online) usage for real-time and batch data.
ML CI/CD pipeline — automatically trains, tests, optimizes, and deploys or updates models using a snapshot of the production data (generated by the feature store) and code from the source control (Git).
Real-Time Serving Pipeline — Rapid deployment of scalable data and ML pipelines using real-time serverless technology, including the API handling, data preparation/enrichment, model serving, ensembles, driving and measuring actions, etc.
Real-Time monitoring and retraining — monitors data, models, and production components and provides a feedback loop for exploring production data, identifying drift, alerting on anomalies or data quality issues, triggering re-training jobs, measuring business impact, etc.
While each of those steps may be independent, they still require tight integration. For example:
The training jobs need to obtain features from the feature store and update the feature store with metadata, which will be used in the serving or monitoring.
The real-time pipeline needs to enrich incoming events with features stored in the feature store, and may use feature metadata (policies, statistics, schema, etc.) to impute missing data or validate data quality.
The monitoring layer must collect real-time inputs and outputs from the real-time pipeline and compare it with features data/metadata from the feature store or model metadata generated by the training layer, and it needs to write all the fresh production data back to the feature store so it can be used for various tasks such as data analysis, model re-training (on fresh data), model improvements.
When one of the components detailed above is updated, it immediately impacts the feature generation, the model serving pipeline, and the monitoring. MLRun applies versioning to each component, as well as versioning and rolling upgrades across components.
Basic components¶
MLRun has the following main components that are used throughout the system:
Project — a container for organizing all of your work on a particular activity. Projects consist of metadata, source code, workflows, data and artifacts, models, triggers, and member management for user collaboration. Read more in Projects.
Function — a software package with one or more methods and runtime-specific attributes (such as image, command, arguments, and environment). Read more in MLRun serverless functions and Creating and using functions.
Run — an object that contains information about an executed function. The run object is created as a result of running a function, and contains the function attributes (such as arguments, inputs, and outputs), as well the execution status and results (including links to output artifacts). Read more in Runs, functions, and workflows.
Artifact — versioned data artifacts (such as data sets, files and models) are produced or consumed by functions, runs, and workflows. Read more in Artifacts and models.
Workflow — defines a functions pipeline or a directed acyclic graph (DAG) to execute using Kubeflow Pipelines or MLRun Real-time serving pipelines. Read more in Project workflows and automation
UI — a graphical user interface (dashboard) for displaying and managing projects and their contained experiments, artifacts, and code.