
Artifacts#
An artifact is any data that is produced and/or consumed by functions, jobs, or pipelines.
There are several types of Artifacts. The type of the Artifact is reflected in the
kind attribute of each Artifact. These types are also
used for grouping the artifacts in the UI.
The main kinds of artifacts are:
Files — Files, directories, images, figures, and plot lines
Datasets — Any data, such as tables and DataFrames
Models — All trained models
Feature Store Objects — Feature sets and feature vectors
Artifacts metadata is stored in the MLRun database.
In this section
See also:
View artifacts in the UI#
Artifacts that are stored in certain paths (see Artifact path) can be viewed and managed in the UI. In the Project page, select the type of artifact you want to view from the left-hand menu: Feature Store (for feature-sets, feature-vectors, and features), Datasets, Models, and Artifacts (holds everything not in the other categories).
Example dataset artifact screen:
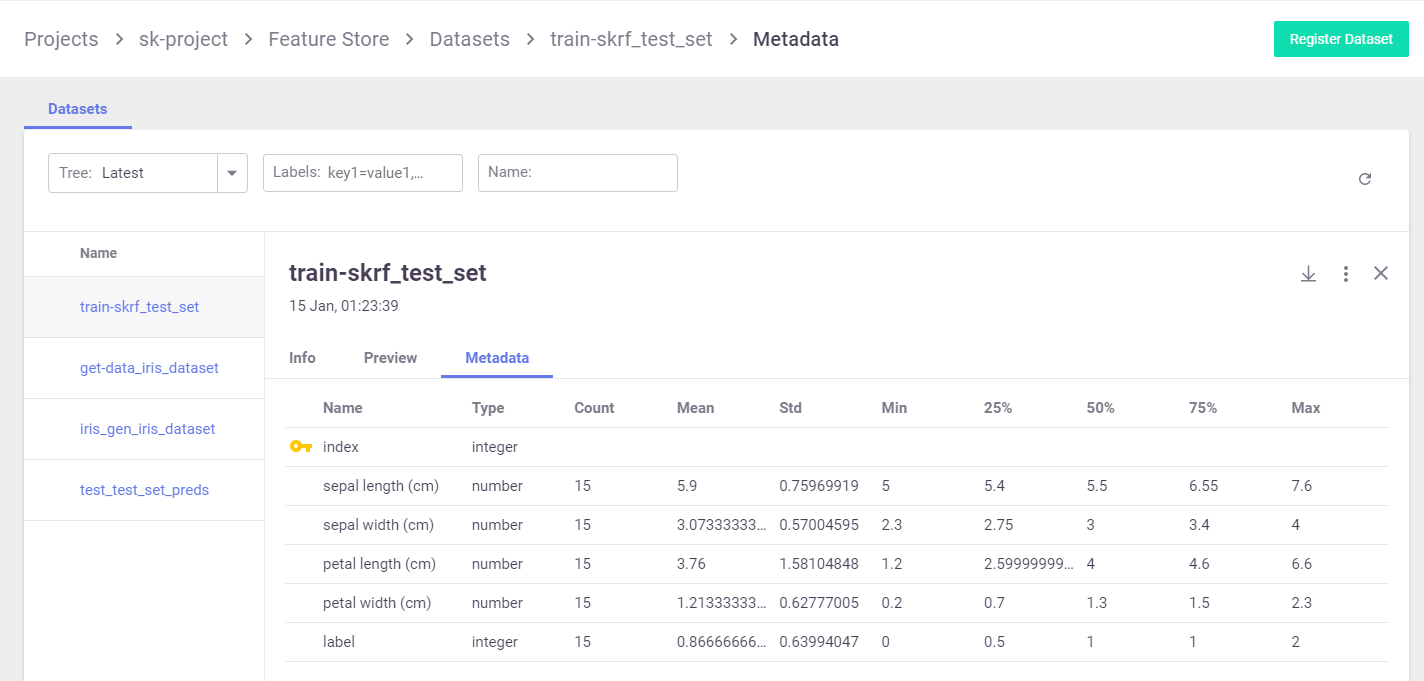
Artifacts that were generated by an MLRun job can also be viewed from the Jobs > Artifacts tab.
You can search the artifacts based on time and labels, and you can filter the artifacts by tag type. For each artifact, you can view its content, its location, the artifact type, labels, the producer of the artifact, the artifact owner, last update date, and type-specific information. You can download the artifact. You can also tag and remove tags from artifacts using the UI.
The UI limits the artifact query display to 1000 records. You can add filters to narrow the query results. (Each search could results in a different set of records.)
View artifacts with the SDK#
View artifacts with project.list_artifacts(), for example:
# Get the latest version of all artifacts in project
latest_artifacts = project.list_artifacts(tag="latest")
# Check the different artifact versions for a specific artifact, return as objects list
result_versions = project.list_artifacts("results", tag="*").to_objects()
See the full parameter list in list_artifacts() and list_artifacts().
Artifact path#
Any path that is supported by MLRun can be used to store artifacts. However, only artifacts that are stored in paths that are system-configured as "allowed" in the MLRun service are visible in the UI. These are:
V3IO paths
cloud storage paths —
v3io://,s3://,az://,gcs://,gs://.
http://paths are not visible due to security reasons.DBFS (Databricks file system):
dbfs://
Jobs use the default or job specific artifact_path parameter to determine where the artifacts are stored.
The default artifact_path can be specified at the cluster level, client level, project level, or job level
(at that precedence order), or can be specified as a parameter in the specific log operation.
You can set the default artifact_path for your environment using the set_environment() function.
You can override the default artifact_path configuration by setting the artifact_path parameter of
the MlrunProject object, setting the artifact path for objects belonging to that project. You can use variables in the artifacts path,
such as {{project}} for the name of the running project or {{run.uid}} for the current job/pipeline run UID.
(The default artifacts path uses {{project}}.) The following example configures the artifacts path to an
artifacts directory in the current active directory (./artifacts)
project.artifact_path='./artifacts'
For Iguazio AI Platform users
In the platform, the default artifacts path is the /v3io/projects/<project name>/artifacts
(for example, /v3io/projects/myproject/artifacts for a “myproject” project).
Saving artifacts in run-specific paths#
When you specify {{run.uid}}, the artifacts for each job are stored in a dedicated directory for each executed job.
Under the artifact path, you should see the source-data file in a new directory whose name is derived from the unique run ID.
Otherwise, the same artifacts directory is used in all runs, and the artifacts for newer runs override those from the previous runs.
As previously explained, set_environment returns a tuple with the project name and artifacts path.
You can optionally save your environment's artifacts path to a variable, as demonstrated in the previous steps.
You can then use the artifacts-path variable to extract paths to task-specific artifact subdirectories.
For example, the following code extracts the path to the artifacts directory of a training task, and saves the path
to a training_artifacts variable:
from os import path
training_artifacts = path.join(artifact_path, "training")
Note
The artifacts path uses data store URLs, which are not necessarily local file paths
(for example, s3://bucket/path). Be careful not to use such paths with general file utilities.
Artifact URIs, versioning, and metadata#
Artifacts have unique URIs in the form store://<type>/<project>/<key/path>[:tag].
The URI is automatically generated by log_artifact and can be used as input to jobs, functions, pipelines, etc.
Artifacts are versioned. Each unique version has a unique IDs (uid) and can have a tag label.
When the tag is not specified, it uses the latest version.
Artifact metadata and objects can be accessed through the SDK or downloaded from the UI (as YAML files). They host common and object specific metadata such as:
Common metadata: name, project, updated, version info
How they were produced (user, job, pipeline, etc.)
Lineage data (sources used to produce that artifact)
Information about formats, schema, sample data
Links to other artifacts (e.g. a model can point to a chart)
Type-specific attributes
Artifacts can be obtained via the SDK through type specific APIs or using generic artifact APIs such as:
get_dataitem()- get theDataItemobject for reading/downloading the artifact contentget_store_resource()- get the artifact object
Example artifact URLs:
store://artifacts/default/my-table
store://artifacts/sk-project/train-model:e95f757e-7959-4d66-b500-9f6cdb1f0bc7
store://feature-sets/stocks/quotes:v2
store://feature-vectors/stocks/enriched-ticker
Deleting artifacts#
Artifacts are comprised of two parts: an artifact object that points to the artifact data; and the artifact data (files). You can delete artifacts from a specific project and choose what you want to delete. You cannot delete artifacts of type: ModelArtifact, DirArtifact, or DatasetArtifact that has more than one file. Deleting artifact data is supported for V3IO, Google, Azure, DBFS, Filestore, and S3.
The options for delete_artifact():
metadata-only: Delete only the artifact object. The related artifact data remains.
data-optional: Delete the artifact object and the data. If data deletion is unsuccessful, deletes only the object.
data-force: Delete the artifact object and the data. If data deletion is unsuccessful, the object is also not deleted.
For example:
artifact = project.get_artifact("name")
project.delete_artifact(artifact, deletion_strategy=mlrun.common.schemas.artifact.ArtifactsDeletionStrategies.data_force, secrets={"secret1": "user-secret"})
Be sure to include secrets if additional credentials are needed to access the artifact data beyond those already specified as project secrets.