
Git best practices#
This section provides an overview of developing and deploying ML applications using MLRun and Git. It covers the following:
Note
This section assumes basic familiarity with version control software such as GitHub, GitLab, etc. If you're new to Git and version control, see the GitHub Hello World documentation.
See also
MLRun and Git Overview#
As a best practice, your MLRun project should be backed by a Git repo. This allows you to keep track of your code in source control as well as utilize your entire code library within your MLRun functions.
The typical lifecycle of a project is as follows:
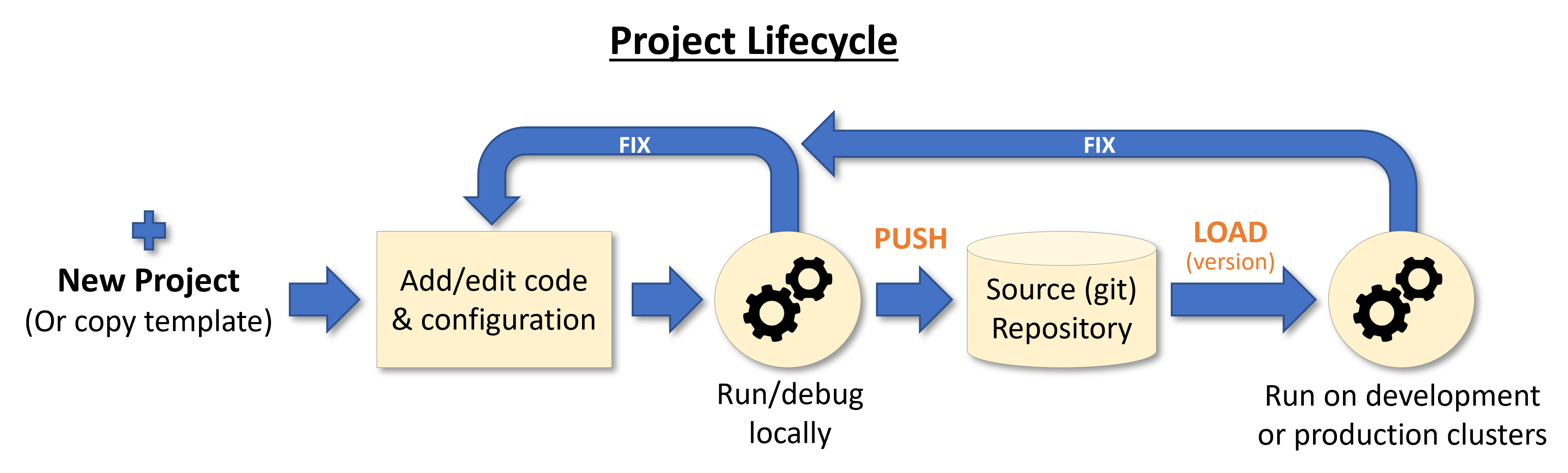
Many people like to develop locally on their laptops, Jupyter environments, or local IDE before submitting the code to Git and running on the larger cluster. See Set up your client environment for more details.
Loading the code from container vs. loading the code at runtime#
MLRun supports two approaches to loading the code from Git:
Loading the code from container (default behavior)
Before using this option, you must build the function with thebuild_functionmethod. The image for the MLRun function is built once, and consumes the code in the repo. This is the preferred approach for production workloads. For example:
project.set_source(source="git://github.com/mlrun/project-archive.git")
fn = project.set_function(
name="myjob", handler="job_func.job_handler",
image="mlrun/mlrun", kind="job", with_repo=True,
)
project.build_function(fn)
Loading the code at runtime
The MLRun function pulls the source code directly from Git at runtime. This is a simpler approach during development that allows for making code changes without re-building the image each time. For example:
project.set_source(source="git://github.com/mlrun/project-archive.git", pull_at_runtime=True)
fn = project.set_function(
name="nuclio", handler="nuclio_func:nuclio_handler",
image="mlrun/mlrun", kind="nuclio", with_repo=True,
)
Note
If your nuclio_func is inside a folder, the path is:
handler="folder1.folder2.folder3.nuclio_func:nuclio_handler"
Common tasks#
Setting up a new MLRun project repo#
Initialize your repo using the command line as per this guide or using your version control software of choice (e.g. GitHub, GitLab, etc.).
git init ...
git add ...
git commit -m ...
git remote add origin ...
git branch -M <BRANCH>
git push -u origin <BRANCH>
Clone the repo to the local environment where the MLRun client is installed (e.g. Jupyter, VSCode, etc.) and navigate to the repo.
Note
It is assumed that your local environment has the required access to pull a private repo.
git clone <MY_REPO>
cd <MY_REPO>
Initialize a new MLRun project with the context pointing to your newly cloned repo.
import mlrun
project = mlrun.get_or_create_project(name="my-super-cool-project", context="./")
Set the MLRun project source with the desired
pull_at_runtimebehavior (see Loading the code from container vs. loading the code at runtime for more info). Also setGIT_TOKENin MLRun project secrets for working with private repos.
# Notice the prefix has been changed to git://
project.set_source(source="git://github.com/mlrun/project-archive.git", pull_at_runtime=True)
project.set_secrets(secrets={"GIT_TOKEN" : "XXXXXXXXXXXXXXX"}, provider="kubernetes")
Register any MLRun functions or workflows and save. Make sure
with_repoisTruein order to add source code to the function.
project.set_function(name='train_model', func='train_model.py', kind='job', image='mlrun/mlrun', with_repo=True)
project.set_workflow(name='training_pipeline', workflow_path='training_pipeline.py')
project.save()
Push additions to Git.
git add ...
git commit -m ...
git push ...
Run the MLRun function/workflow. The source code is added to the function and is available via imports as expected.
project.run_function(function="train_model")
project.run(name="training_pipeline")
Running an existing MLRun project repo#
Clone an existing MLRun project repo to your local environment where the MLRun client is installed (e.g. Jupyter, VSCode, etc.) and navigate to the repo.
git clone <MY_REPO>
cd <MY_REPO>
Load the MLRun project with the context pointing to your newly cloned repo. MLRun is looking for a
project.yamlfile in the root of the repo.
project = mlrun.load_project(context="./")
Optionally enable
pull_at_runtimefor easier development. Also setGIT_TOKENin the MLRun Project secrets for working with private repos.
# source=None will use current Git source
project.set_source(source=None, pull_at_runtime=True)
project.set_secrets(secrets={"GIT_TOKEN" : "XXXXXXXXXXXXXXX"}, provider="kubernetes")
Run the MLRun function/workflow. The source code is added to the function and is available via imports as expected.
project.run_function(function="train_model")
project.run(name="training_pipeline")
Note
If another user previously ran the project in your MLRun environment, ensure that your user has project permissions (otherwise you may not be able to view or run the project).
Pushing changes to the MLRun project repo#
Edit the source code/functions/workflows in some way.
Check-in changes to Git.
git add ...
git commit -m ...
git push ...
If
pull_at_runtime=False, re-build the Docker image. Ifpull_at_runtime=True, skip this step.
import mlrun
project = mlrun.load_project(context="./")
project.build_function("my_updated_function")
Run the MLRun function/workflow. The source code with changes is added to the function and is available via imports as expected.
project.run_function(function="train_model")
project.run(name="training_pipeline")
Utilizing different branches#
Check out the desired branch in the local environment.
git checkout <BRANCH>
Update the desired branch in MLRun project. Optionally, save if the branch should be used for future runs.
project.set_source(
source="git://github.com/igz-us-sales/mlrun-git-example.git#spanish",
pull_at_runtime=True
)
project.save()
Run the MLRun function/workflow. The source code from desired branch is added to the function and is available via imports as expected.
project.run_function("greetings")