
Using the built-in training function#
The MLRun Hub includes, among other things, training functions. The most commonly used function for training is auto_trainer, which includes the following handlers:
Train#
The main and default handler of any training function is called "train". In the Auto Trainer this handler performs
an ML training function using SciKit-Learn's API, meaning the function follows the structure below:
Get the data: Get the dataset passed to a local path.
Split the data into datasets: Split the given data into a training set and a testing set.
Get the model: Initialize a model instance out of a given class or load a provided model
The supported classes are anything based onsklearn.Estimator,xgboost.XGBModel,lightgbm.LGBMModel, including custom code as well.Train: Call the model's
fitmethod to train it on the training set.Test: Test the model on the testing set.
Log: Calculate the metrics and produce the artifacts to log the results and plots.
MLRun orchestrates all of the above steps. The training is done with the shortcut function apply_mlrun that
enables the automatic logging and additional features.
To start, run import mlrun and create a project:
import mlrun
# Set the base project name
project_name_base = "training-test"
# Initialize the MLRun project object
project = mlrun.get_or_create_project(
project_name_base, context="./", user_project=True
)
Next, import the Auto Trainer from the Function Hub using MLRun's import_function function:
auto_trainer = project.set_function(mlrun.import_function("hub://auto_trainer"))
The following example trains a Random Forest model:
dataset_url = "https://s3.wasabisys.com/iguazio/data/function-marketplace-data/xgb_trainer/classifier-data.csv"
train_run = auto_trainer.run(
handler="train",
inputs={"dataset": dataset_url},
params={
# Model parameters:
"model_class": "sklearn.ensemble.RandomForestClassifier",
"model_kwargs": {
"max_depth": 8
}, # Could be also passed as "MODEL_max_depth": 8
"model_name": "MyModel",
# Dataset parameters:
"drop_columns": ["feat_0", "feat_2"],
"train_test_split_size": 0.2,
"random_state": 42,
"label_columns": "labels",
},
)
Outputs#
train_run.outputs returns all the outputs. The outputs are:
Trained model: The trained model is logged as a
ModelArtifactwith all the following artifacts registered to it.Test dataset: The test set used to test the model post training is logged as a
DatasetArtifact.Plots: Informative plots regarding the model like confusion matrix and features importance are drawn and logged as
PlotArtifacts.Results: List of all the calculations of metrics tested on the testing set.
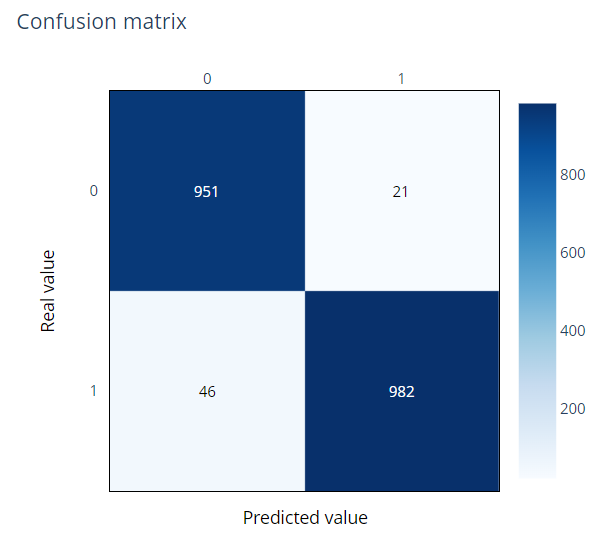
For instance, calling train_run.artifact('confusion-matrix').show() shows the following confusion matrix:
Parameters#
To view the parameters of train, expand the section below:
train handler parameters:
Model Parameters
Parameters to initialize a new model object or load a logged one for retraining.
model_class:str— The class of the model to initialize. Can be a module path like"sklearn.linear_model.LogisticRegression"or a custom model passed through the custom objects parameters below. Only one ofmodel_classandmodel_pathcan be given.model_path:str— AModelArtifactURI to load and retrain. Only one ofmodel_classandmodel_pathcan be given.model_kwargs:dict— Additional parameters to pass onto the initialization of the model object (the model's class__init__method).
Data parameters
Parameters to get a dataset and prepare it for training, splitting into training and testing if required.
dataset:Union[str, list, dict]— The dataset to train the model on.Can be passed as part of
inputsto be parsed asmlrun.DataItem, meaning it supports either a URI or a FeatureVector.Can be passed as part of
params, meaning it can be alistor adict.
drop_columns:Union[str, int, List[str], List[int]]— Columns to drop from the dataset. Can be passed as strings representing the column names or integers representing the column numbers.test_set:Union[str, list, dict]— The test set to test the model with post training. Notice only one oftest_setortrain_test_split_sizeis expected.Can be passed as part of
inputsto be parsed asmlrun.DataItem, meaning it supports either a URI or a FeatureVector.Can be passed as part of
params, meaning it can be alistor adict.
train_test_split_size:float=0.2— The proportion of the dataset to include in the test split. The size of the Training set is set to the complement of this value. Must be between 0.0 and 1.0. Defaults to 0.2label_columns:Union[str, int, List[str], List[int]]— The target label(s) of the column(s) in the dataset. Can be passed as strings representing the column names or integers representing the column numbers.random_state:int- Random state (seed) fortrain_test_split.
Train parameters
Parameters to pass to the fit method of the model object.
train_kwargs:dict— Additional parameters to pass onto thefitmethod.
Logging parameters
Parameters to control the automatic logging feature of MLRun. You can adjust the logging outputs as relevant and if not passed, a default list of artifacts and metrics is produced and calculated.
model_name:str="model" — The model’s name to use for storing the model artifact, defaults to ‘model’.tag:str— The model’s tag to log with.sample_set:Union[str, list, dict]— A sample set of inputs for the model for logging its stats alongside the model in favor of model monitoring. If not given, the training set is used instead.Can be passed as part of
inputsto be parsed asmlrun.DataItem, meaning it supports either a URI or a FeatureVector.Can be passed as part of
params, meaning it can be alistor adict.
_artifacts:Dict[str, Union[list, dict]]— Additional artifacts to produce post training. See theArtifactsLibraryof the desired framework to see the available list of artifacts._metrics:Union[List[str], Dict[str, Union[list, dict]]]— Additional metrics to calculate post training. See how to pass metrics and custom metrics in theMetricsLibraryof the desired framework.apply_mlrun_kwargs:dict— Framework specificapply_mlrunkey word arguments. Refer to the framework of choice to know more (SciKit-Learn, XGBoost or LightGBM)
Custom objects parameters
Parameters to include custom objects like custom model class, metric code and artifact plan. Keep in mind that the
model artifact created is logged with the custom objects, so if model_path is used, the custom objects used to
train it are not required for loading it, it happens automatically.
custom_objects_map:Union[str, Dict[str, Union[str, List[str]]]]— A map of all the custom objects required for loading, training and testing the model. Can be passed as a dictionary or a json file path. Each key is a path to a python file and its value is the custom object name to import from it. If multiple objects needed to be imported from the same py file a list can be given. For example:{ "/.../custom_model.py": "MyModel", "/.../custom_objects.py": ["object1", "object2"] }
All the paths are accessed from the given 'custom_objects_directory', meaning each py file is read from 'custom_objects_directory/
Note
The custom objects are imported in the order they came in this dictionary (or json). If a custom object is dependent on another, make sure to put it below the one it relies on.
custom_objects_directory: Path to the directory with all the python files required for the custom objects. Can be passed as a zip file as well (and are extracted during the start of the run).Note
The parameters for additional arguments
model_kwargs,train_kwargsandapply_mlrun_kwargscan be also passed in the globalkwargswith the matching prefixes:"MODEL_","TRAIN_","MLRUN_".
Evaluate#
The "evaluate" handler is used to test the model on a given testing set and log its results. This is a common phase in
every model lifecycle and should be done periodically on updated testing sets to confirm that your model is still relevant.
The function uses SciKit-Learn's API for evaluation, meaning the function follows the structure below:
Get the data: Get the testing dataset passed to a local path.
Get the model: Get the model object out of the
ModelArtifactURI.Predict: Call the model's
predict(andpredict_probaif needed) method to test it on the testing set.Log: Test the model on the testing set and log the results and artifacts.
MLRun orchestrates all of the above steps. The evaluation is done with the shortcut function apply_mlrun that
enables the automatic logging and further features.
To evaluate the test-set, use the following command:
evaluate_run = auto_trainer.run(
handler="evaluate",
inputs={"dataset": train_run.outputs["test_set"]},
params={
"model": train_run.outputs["model"],
"label_columns": "labels",
},
)
Outputs#
evaluate_run.outputs returns all the outputs. The outputs are:
Evaluated model: The evaluated model's
ModelArtifactis updated with all the following artifacts registered to it.Test dataset: The test set used to test the model post-training is logged as a
DatasetArtifact.Plots: Informative plots regarding the model like confusion matrix and features importance are drawn and logged as
PlotArtifacts.Results: List of all the calculations of metrics tested on the testing set.
Parameters#
To view the parameters of evaluate, expand the section below:
evaluate handler parameters:
Model Parameters
Parameters to load a logged model.
model_path:str— AModelArtifactURI to load.
Data parameters
Parameters to get a dataset and prepare it for training, splitting into training and testing if required.
dataset:Union[str, list, dict]— The dataset to train the model on.Can be passed as part of
inputsto be parsed asmlrun.DataItem, meaning it supports either a URI or a FeatureVector.Can be passed as part of
params, meaning it can be alistor adict.
drop_columns:Union[str, int, List[str], List[int]]— columns to drop from the dataset. Can be passed as strings representing the column names or integers representing the column numbers.label_columns:Union[str, int, List[str], List[int]]— The target label(s) of the column(s) in the dataset. Can be passed as strings representing the column names or integers representing the column numbers.
Predict parameters
Parameters to pass to the predict method of the model object.
predict_kwargs:dict— Additional parameters to pass onto thepredictmethod.
Logging parameters
Parameters to control the automatic logging feature of MLRun. You can adjust the logging outputs as relevant, and if not passed, a default list of artifacts and metrics is produced and calculated.
_artifacts:Dict[str, Union[list, dict]]— Additional artifacts to produce post training. See theArtifactsLibraryof the desired framework to see the available list of artifacts._metrics:Union[List[str], Dict[str, Union[list, dict]]]— Additional metrics to calculate post training. See how to pass metrics and custom metrics in theMetricsLibraryof the desired framework.apply_mlrun_kwargs:dict— Framework specificapply_mlrunkey word arguments. Refer to the framework of choice to know more (SciKit-Learn, XGBoost or LightGBM).
Custom objects parameters
Parameters to include custom objects for the evaluation like custom metric code and artifact plans. Keep in mind that the custom objects used to train the model are not required for loading it, it happens automatically.
custom_objects_map:Union[str, Dict[str, Union[str, List[str]]]]— A map of all the custom objects required for loading, training and testing the model. Can be passed as a dictionary or a json file path. Each key is a path to a python file and its value is the custom object name to import from it. If multiple objects needed to be imported from the same py file a list can be given. For example:{ "/.../custom_metric.py": "MyMetric", "/.../custom_plans.py": ["plan1", "plan2"] }
All the paths are accessed from the given 'custom_objects_directory', meaning each py file is read from the 'custom_objects_directory/
Note
The custom objects are imported in the order they came in this dictionary (or json). If a custom object is depended on another, make sure to put it below the one it relies on.
custom_objects_directory— Path to the directory with all the python files required for the custom objects. Can be passed as a zip file as well (iti is extracted during the start of the run).Note
The parameters for additional arguments
predict_kwargsandapply_mlrun_kwargscan be also passed in the globalkwargswith the matching prefixes:"PREDICT_","MLRUN_".