
Part 1: Data ingestion#
This demo showcases financial fraud prevention using the MLRun feature store to define complex features that help identify fraud. Fraud prevention specifically is a challenge because it requires processing raw transaction and events in real-time, and being able to quickly respond and block transactions before they occur.
Note
This demo works with the online feature store, which is currently not part of the Open Source default deployment.
To address this, you create a development pipeline and a production pipeline. Both pipelines share the same feature engineering and model code, but serve data very differently. Furthermore, you automate the data and model monitoring process, identify drift and trigger retraining in a CI/CD pipeline. This process is described in the diagram below:
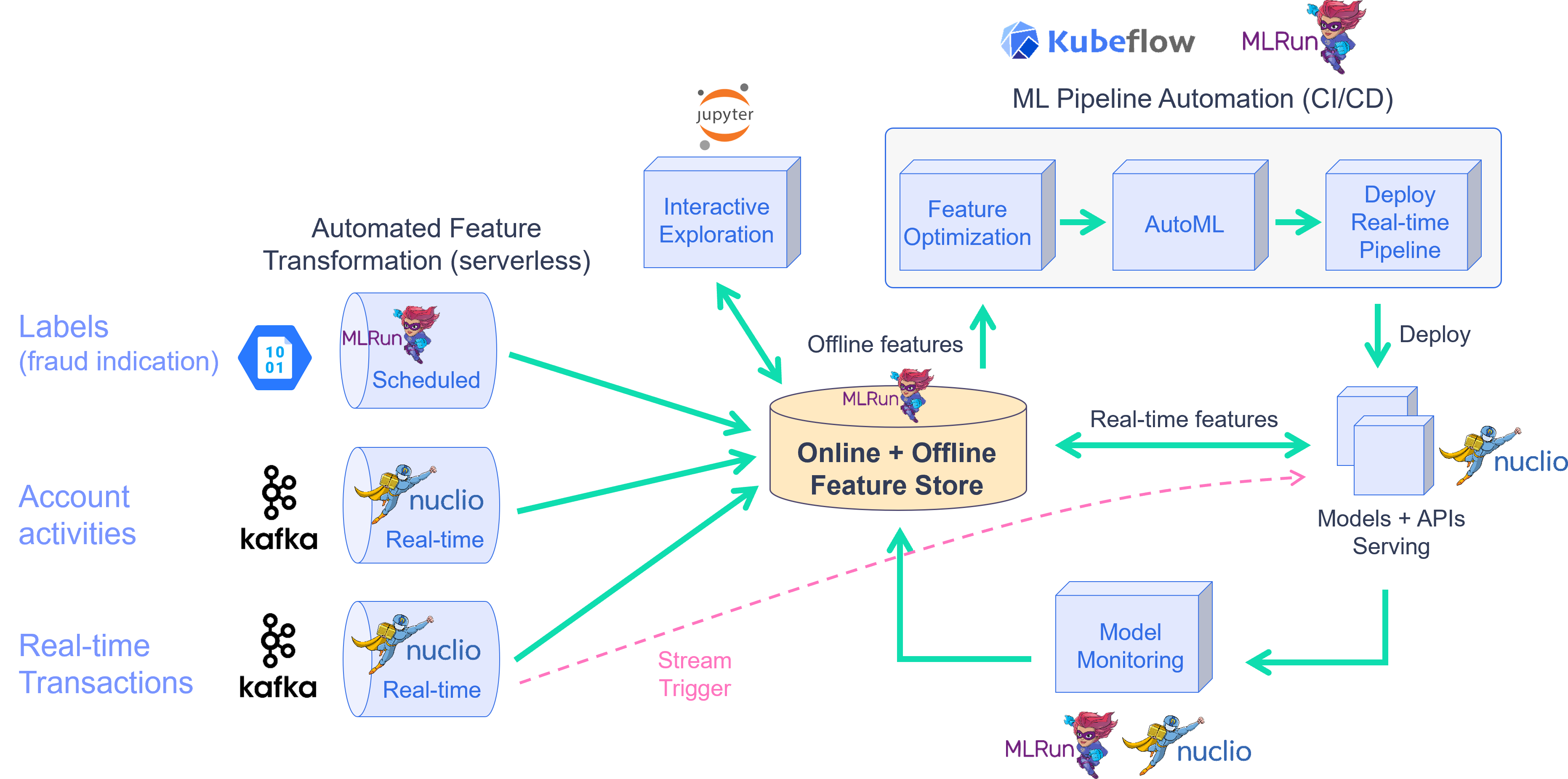
By the end of this tutorial you’ll learn how to:
Create an ingestion pipeline for each data source.
Define preprocessing, aggregation and validation of the pipeline.
Run the pipeline locally within the notebook.
Launch a real-time function to ingest live data.
Schedule a cron to run the task when needed.
The raw data is described as follows:
TRANSACTIONS |
║ |
USER EVENTS |
||
|---|---|---|---|---|
age |
age group value 0-6. Some values are marked as U for unknown |
║ |
source |
The party/entity related to the event |
gender |
A character to define the gender |
║ |
event |
event, such as login or password change |
zipcodeOri |
ZIP code of the person originating the transaction |
║ |
timestamp |
The date and time of the event |
zipMerchant |
ZIP code of the merchant receiving the transaction |
║ |
||
category |
category of the transaction (e.g., transportation, food, etc.) |
║ |
||
amount |
the total amount of the transaction |
║ |
||
fraud |
whether the transaction is fraudulent |
║ |
||
timestamp |
the date and time in which the transaction took place |
║ |
||
source |
the ID of the party/entity performing the transaction |
║ |
||
target |
the ID of the party/entity receiving the transaction |
║ |
||
device |
the device ID used to perform the transaction |
║ |
This notebook introduces how to Ingest different data sources to the Feature Store.
The following FeatureSets are created:
Transactions: Monetary transactions between a source and a target.
Events: Account events such as account login or a password change.
Label: Fraud label for the data.
!/User/align_mlrun.sh
Both server & client are aligned (1.7.0rc40).
project_name = "fraud-demo"
import mlrun
# Initialize the MLRun project object
project = mlrun.get_or_create_project(project_name, context="./", user_project=True)
> 2024-09-12 06:38:52,635 [info] Project loaded successfully: {"project_name":"fraud-demo-jill"}
Step 1 - Fetch, process and ingest the datasets#
1.1 - Transactions#
Transactions#
import pandas as pd
# Fetch the transactions dataset from the server
transactions_data = pd.read_csv(
"https://s3.wasabisys.com/iguazio/data/fraud-demo-mlrun-fs-docs/data.csv",
parse_dates=["timestamp"],
)
# use only first 50k
transactions_data = transactions_data.sort_values(by="source", axis=0)[:10000]
# Adjust the samples timestamp for the past 2 days
transactions_data = adjust_data_timespan(transactions_data, new_period="2d")
# Sorting after adjusting timestamps
transactions_data = transactions_data.sort_values(by="timestamp", axis=0)
# Preview
transactions_data.head(3)
| step | age | gender | zipcodeOri | zipMerchant | category | amount | fraud | timestamp | source | target | device | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 274633 | 91 | 5 | F | 28007 | 28007 | es_transportation | 26.92 | 0 | 2024-09-10 06:39:33.730952000 | C1022153336 | M1823072687 | 33832bb8607545df97632a7ab02d69c4 |
| 286902 | 94 | 2 | M | 28007 | 28007 | es_transportation | 48.22 | 0 | 2024-09-10 06:39:52.024577913 | C1006176917 | M348934600 | fadd829c49e74ffa86c8da3be75ada53 |
| 416998 | 131 | 3 | M | 28007 | 28007 | es_transportation | 17.56 | 0 | 2024-09-10 06:39:57.131747939 | C1010936270 | M348934600 | 58d0422a50bc40c89d2b4977b2f1beea |
Transactions - create a feature set and preprocessing pipeline#
Create the feature set (data pipeline) definition for the credit transaction processing that describes the
offline/online data transformations and aggregations.
The feature store automatically adds an offline parquet target and an online NoSQL target by using set_targets().
The data pipeline consists of:
Extracting the data components (hour, day of week)
Mapping the age values
One hot encoding for the transaction category and the gender
Aggregating the amount (avg, sum, count, max over 2/12/24 hour time windows)
Aggregating the transactions per category (over 14 days time windows)
Writing the results to offline (Parquet) and online (NoSQL) targets
# Import MLRun's Feature Store
import mlrun.feature_store as fstore
from mlrun.feature_store.steps import OneHotEncoder, MapValues, DateExtractor
# Define the transactions FeatureSet
transaction_set = fstore.FeatureSet(
"transactions",
entities=[fstore.Entity("source")],
timestamp_key="timestamp",
description="transactions feature set",
)
# Define and add value mapping
main_categories = [
"es_transportation",
"es_health",
"es_otherservices",
"es_food",
"es_hotelservices",
"es_barsandrestaurants",
"es_tech",
"es_sportsandtoys",
"es_wellnessandbeauty",
"es_hyper",
"es_fashion",
"es_home",
"es_contents",
"es_travel",
"es_leisure",
]
# One Hot Encode the newly defined mappings
one_hot_encoder_mapping = {
"category": main_categories,
"gender": list(transactions_data.gender.unique()),
}
# Define the graph steps
transaction_set.graph.to(
DateExtractor(parts=["hour", "day_of_week"], timestamp_col="timestamp")
).to(MapValues(mapping={"age": {"U": "0"}}, with_original_features=True)).to(
OneHotEncoder(mapping=one_hot_encoder_mapping)
)
# Add aggregations for 2, 12, and 24 hour time windows
transaction_set.add_aggregation(
name="amount",
column="amount",
operations=["avg", "sum", "count", "max"],
windows=["2h", "12h", "24h"],
period="1h",
)
# Add the category aggregations over a 14 day window
for category in main_categories:
transaction_set.add_aggregation(
name=category,
column=f"category_{category}",
operations=["sum"],
windows=["14d"],
period="1d",
)
# Add default (offline-parquet & online-nosql) targets
transaction_set.set_targets()
# Plot the pipeline so you can see the different steps
transaction_set.plot(rankdir="LR", with_targets=True)

Transactions - ingestion#
# Ingest your transactions dataset through your defined pipeline
transactions_df = transaction_set.ingest(
transactions_data, infer_options=fstore.InferOptions.default()
)
transactions_df.head(3)
| amount_sum_2h | amount_sum_12h | amount_sum_24h | amount_count_2h | amount_count_12h | amount_count_24h | amount_max_2h | amount_max_12h | amount_max_24h | amount_avg_2h | ... | category_es_contents | category_es_travel | category_es_leisure | amount | fraud | timestamp | target | device | timestamp_hour | timestamp_day_of_week | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| source | |||||||||||||||||||||
| C1022153336 | 26.92 | 26.92 | 26.92 | 1.0 | 1.0 | 1.0 | 26.92 | 26.92 | 26.92 | 26.92 | ... | 0 | 0 | 0 | 26.92 | 0 | 2024-09-10 06:39:33.730952000 | M1823072687 | 33832bb8607545df97632a7ab02d69c4 | 6 | 1 |
| C1006176917 | 48.22 | 48.22 | 48.22 | 1.0 | 1.0 | 1.0 | 48.22 | 48.22 | 48.22 | 48.22 | ... | 0 | 0 | 0 | 48.22 | 0 | 2024-09-10 06:39:52.024577913 | M348934600 | fadd829c49e74ffa86c8da3be75ada53 | 6 | 1 |
| C1010936270 | 17.56 | 17.56 | 17.56 | 1.0 | 1.0 | 1.0 | 17.56 | 17.56 | 17.56 | 17.56 | ... | 0 | 0 | 0 | 17.56 | 0 | 2024-09-10 06:39:57.131747939 | M348934600 | 58d0422a50bc40c89d2b4977b2f1beea | 6 | 1 |
3 rows × 56 columns
After performing the ingestion process, you can see all of the different features that were created with the help of the UI, as shown in the image below.
1.2 - User events#
User events - fetching#
# Fetch the user_events dataset from the server
user_events_data = pd.read_csv(
"https://s3.wasabisys.com/iguazio/data/fraud-demo-mlrun-fs-docs/events.csv",
index_col=0,
quotechar="'",
parse_dates=["timestamp"],
)
# Adjust to the last 2 days to see the latest aggregations in the online feature vectors
user_events_data = adjust_data_timespan(user_events_data, new_period="2d")
# Preview
user_events_data.head(3)
| source | event | timestamp | |
|---|---|---|---|
| 0 | C1974668487 | details_change | 2024-09-11 15:47:41.318821086 |
| 1 | C1973547259 | login | 2024-09-11 18:49:15.575961508 |
| 2 | C515668508 | login | 2024-09-11 15:22:21.857138302 |
User events - create a feature set and preprocessing pipeline#
Now define the events feature set. This is a pretty straightforward pipeline in which you only "one hot encode" the event categories and save the data to the default targets.
user_events_set = fstore.FeatureSet(
"events",
entities=[fstore.Entity("source")],
timestamp_key="timestamp",
description="user events feature set",
)
# Define and add value mapping
events_mapping = {"event": list(user_events_data.event.unique())}
# One Hot Encode
user_events_set.graph.to(OneHotEncoder(mapping=events_mapping))
# Add default (offline-parquet & online-nosql) targets
user_events_set.set_targets()
# Plot the pipeline so you can see the different steps
user_events_set.plot(rankdir="LR", with_targets=True)

User Events - Ingestion#
# Ingestion of your newly created events feature set
events_df = user_events_set.ingest(user_events_data)
events_df.head(3)
| event_details_change | event_login | event_password_change | timestamp | |
|---|---|---|---|---|
| source | ||||
| C1974668487 | 1 | 0 | 0 | 2024-09-11 15:47:41.318821086 |
| C1973547259 | 0 | 1 | 0 | 2024-09-11 18:49:15.575961508 |
| C515668508 | 0 | 1 | 0 | 2024-09-11 15:22:21.857138302 |
Step 2 - Create a labels data set for model training#
Label set - create a feature set#
This feature set contains the label for the fraud demo. It is ingested directly to the default targets without any changes.
def create_labels(df):
labels = df[["fraud", "timestamp"]].copy()
labels = labels.rename(columns={"fraud": "label"})
labels["timestamp"] = labels["timestamp"].astype("datetime64[ms]")
labels["label"] = labels["label"].astype(int)
return labels
from mlrun.datastore import ParquetTarget
import os
# Define the "labels" feature set
labels_set = fstore.FeatureSet(
"labels",
entities=[fstore.Entity("source")],
timestamp_key="timestamp",
description="training labels",
engine="pandas",
)
labels_set.graph.to(name="create_labels", handler=create_labels)
# specify only Parquet (offline) target since its not used for real-time
target = ParquetTarget(
name="labels", path=f"v3io:///projects/{project.name}/target.parquet"
)
labels_set.set_targets([target], with_defaults=False)
labels_set.plot(with_targets=True)

Label set - ingestion#
# Ingest the labels feature set
labels_df = labels_set.ingest(transactions_data)
labels_df.head(3)
| label | timestamp | |
|---|---|---|
| source | ||
| C1022153336 | 0 | 2024-09-10 06:39:33.730 |
| C1006176917 | 0 | 2024-09-10 06:39:52.024 |
| C1010936270 | 0 | 2024-09-10 06:39:57.131 |
Step 3 - Deploy a real-time pipeline#
When dealing with real-time aggregation, it's important to be able to update these aggregations in real-time.
For this purpose, you create live serving functions that update the online feature store of the transactions
FeatureSet and Events FeatureSet.
Using MLRun's serving runtime, create a nuclio function loaded with your feature set's computational graph definition
and an HttpSource to define the HTTP trigger.
Notice that the implementation below does not require any rewrite of the pipeline logic.
3.1 - Transactions#
Transactions - deploy the feature set live endpoint#
# Create iguazio v3io stream and transactions push API endpoint
transaction_stream = f"v3io:///projects/{project.name}/streams/transaction"
transaction_pusher = mlrun.datastore.get_stream_pusher(transaction_stream)
# Define the source stream trigger (use v3io streams)
# define the `key` and `time` fields (extracted from the Json message).
source = mlrun.datastore.sources.StreamSource(
path=transaction_stream, key_field="source", time_field="timestamp"
)
# Deploy the transactions feature set's ingestion service over a real-time (Nuclio) serverless function
# you can use the run_config parameter to pass function/service specific configuration
transaction_set_endpoint, function = transaction_set.deploy_ingestion_service(
source=source
)
[nuclio] 2024-09-12 06:43:21,453 workerAllocationMode was automatically set to 'static' because explicitAckMode is enabled
> 2024-09-12 06:43:21,453 [warning] Setting function replicas to 1
> 2024-09-12 06:43:21,457 [info] Starting remote function deploy
2024-09-12 06:43:21 (info) Deploying function
2024-09-12 06:43:21 (info) Building
2024-09-12 06:43:21 (info) Staging files and preparing base images
2024-09-12 06:43:21 (warn) Using user provided base image, runtime interpreter version is provided by the base image
2024-09-12 06:43:21 (info) Building processor image
2024-09-12 06:45:07 (info) Build complete
2024-09-12 06:45:15 (info) Function deploy complete
> 2024-09-12 06:45:22,959 [info] Successfully deployed function: {"external_invocation_urls":["fraud-demo-jill-transactions-ingest.default-tenant.app.vmdev94.lab.iguazeng.com/"],"internal_invocation_urls":["nuclio-fraud-demo-jill-transactions-ingest.default-tenant.svc.cluster.local:8080"]}
Transactions - test the feature set HTTP endpoint#
By defining your transactions feature set you can now use MLRun and Storey to deploy it as a live endpoint, ready to ingest new data!
Using MLRun's serving runtime, create a nuclio function loaded with your feature set's computational graph definition
and an HttpSource to define the HTTP trigger.
import requests
import json
# Select a sample from the dataset and serialize it to JSON
transaction_sample = json.loads(transactions_data.sample(1).to_json(orient="records"))[
0
]
transaction_sample["timestamp"] = str(pd.Timestamp.now())
transaction_sample
{'step': 135,
'age': '1',
'gender': 'M',
'zipcodeOri': 28007,
'zipMerchant': 28007,
'category': 'es_food',
'amount': 54.57,
'fraud': 0,
'timestamp': '2024-09-12 06:45:23.045196',
'source': 'C1014010834',
'target': 'M85975013',
'device': '26d74c1ada0048a7b6002731b15b86e1'}
# Post the sample to the ingestion endpoint
requests.post(transaction_set_endpoint, json=transaction_sample).text
'{"id": "9ac1c85a-ee11-4d08-a7c0-8d2b2bf8f68b"}'
3.2 - User events#
User events - deploy the feature set live endpoint#
Deploy the events feature set's ingestion service using the feature set and all the previously defined resources.
# Create iguazio v3io stream and transactions push API endpoint
events_stream = f"v3io:///projects/{project.name}/streams/events"
events_pusher = mlrun.datastore.get_stream_pusher(events_stream)
# Define the source stream trigger (use v3io streams)
# define the `key` and `time` fields (extracted from the Json message).
source = mlrun.datastore.sources.StreamSource(
path=events_stream, key_field="source", time_field="timestamp"
)
# Deploy the transactions feature set's ingestion service over a real-time (Nuclio) serverless function
# you can use the run_config parameter to pass function/service specific configuration
events_set_endpoint, function = user_events_set.deploy_ingestion_service(source=source)
[nuclio] 2024-09-12 06:45:23,248 workerAllocationMode was automatically set to 'static' because explicitAckMode is enabled
> 2024-09-12 06:45:23,250 [warning] Setting function replicas to 1
> 2024-09-12 06:45:23,252 [info] Starting remote function deploy
2024-09-12 06:45:23 (info) Deploying function
2024-09-12 06:45:23 (info) Building
2024-09-12 06:45:24 (info) Staging files and preparing base images
2024-09-12 06:45:24 (warn) Using user provided base image, runtime interpreter version is provided by the base image
2024-09-12 06:45:24 (info) Building processor image
2024-09-12 06:47:09 (info) Build complete
2024-09-12 06:47:17 (info) Function deploy complete
> 2024-09-12 06:47:25,826 [info] Successfully deployed function: {"external_invocation_urls":["fraud-demo-jill-events-ingest.default-tenant.app.vmdev94.lab.iguazeng.com/"],"internal_invocation_urls":["nuclio-fraud-demo-jill-events-ingest.default-tenant.svc.cluster.local:8080"]}
User Events - Test the feature set HTTP endpoint#
# Select a sample from the events dataset and serialize it to JSON
user_events_sample = json.loads(user_events_data.sample(1).to_json(orient="records"))[0]
user_events_sample["timestamp"] = str(pd.Timestamp.now())
user_events_sample
{'source': 'C228882909',
'event': 'password_change',
'timestamp': '2024-09-12 06:47:25.897467'}
# Post the sample to the ingestion endpoint
requests.post(events_set_endpoint, json=user_events_sample).text
'{"id": "5879fb55-587f-4e0b-a71f-3c563ab9d268"}'
Done!#
You've completed Part 1 of the data-ingestion with the feature store. Proceed to Part 2 to learn how to train an ML model using the feature store data.