
Installation and setup guide #
This guide outlines the steps for installing and running MLRun.
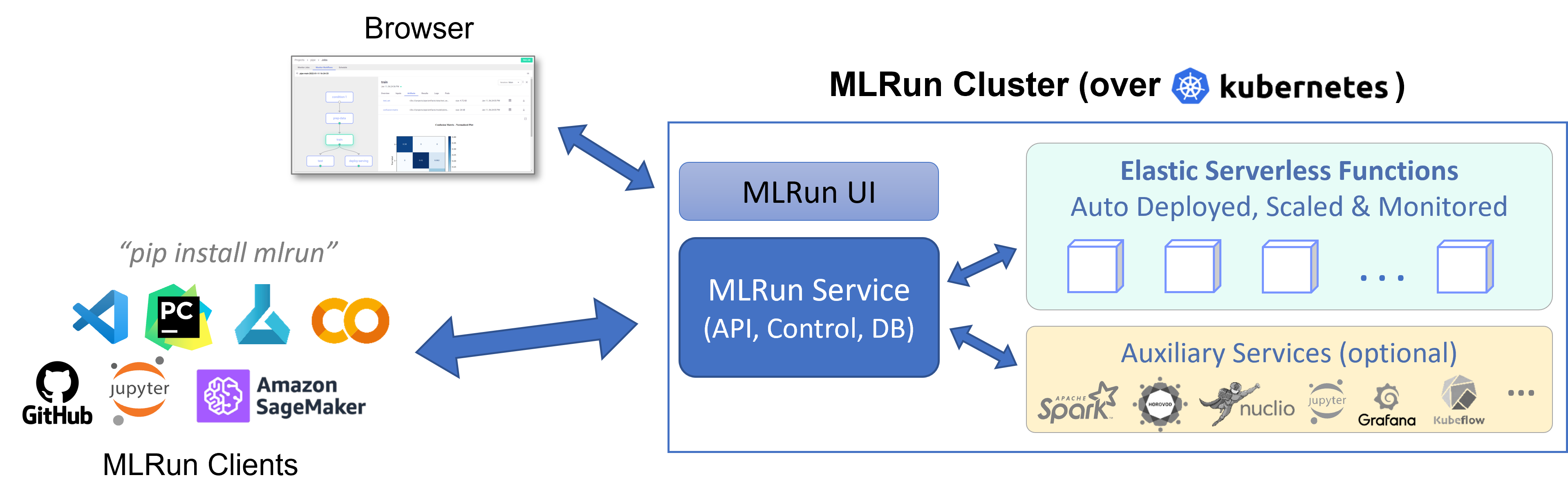
MLRun has two main components, the service and the client (SDK and UI):
MLRun service runs over Kubernetes (can also be deployed using local Docker for demo and test purposes). It can orchestrate and integrate with other open source open source frameworks, as shown in the following diagram.
MLRun client SDK is installed in your development environment and interacts with the service using REST API calls.
This release of MLRun supports only Python 3.9 for both the server and the client.
In this section
Deployment options#
There are several deployment options:
Local deployment: Deploy a Docker on your laptop or on a single server. This option is good for testing the waters or when working in a small scale environment. It's limited in terms of computing resources and scale, but simpler for deployment.
Kubernetes cluster: Deploy an MLRun server on Kubernetes. This option deploys MLRun on a Kubernetes cluster, which supports elastic scaling. Yet, it is more complex to install as it requires you to install Kubernetes on your own.
Amazon Web Services (AWS): Deploy an MLRun server on AWS. This option is the easiest way to install MLRun cluster and use cloud-based services. The MLRun software is free of charge, however, there is a cost for the AWS infrastructure services.
Iguazio's Managed Service: A commercial offering by Iguazio. This is the fastest way to explore the full set of MLRun functionalities.
Note that Iguazio provides a 14 day free trial.
Set up your client#
You can work with your favorite IDE (e.g. Pycharm, VScode, Jupyter, Colab, etc.). Read how to configure your client against the deployed MLRun server in Set up your environment .
Once you have installed and configured MLRun, follow the Quick Start tutorial and additional Tutorials and Examples to learn how to use MLRun to develop and deploy machine learning applications to production.
MLRun client backward compatibility#
Starting from MLRun v1.3.0, the MLRun server is compatible with the client and images of the previous two minor MLRun releases. When you upgrade to v1.3.0, for example, you can continue to use your v1.1- and v1.2-based images, but v1.0-based images are not compatible.
Important
Images from 0.9.0 are not compatible with 0.10.0. Backward compatibility starts from 0.10.0.
When you upgrade the MLRun major version, for example 0.10.x to 1.0.x, there is no backward compatibility.
The feature store is not backward compatible.
When you upgrade the platform, for example from 3.2 to 3.3, the clients should be upgraded. There is no guaranteed compatibility with an older MLRun client after a platform upgrade.
See also Images and their usage in MLRun.
Security#
Non-root user support#
By default, MLRun assigns the root user to MLRun runtimes and pods. You can improve the security context by changing the security mode, which is implemented by Iguazio during installation, and applied system-wide:
Override: Use the user id of the user that triggered the current run or use the nogroupid for group id. Requires Iguazio v3.5.1.
Disabled: Security context is not auto applied (the system applies the root user). (default)
Security context#
If your system is configured in disabled mode, you can apply the security context to individual runtimes/pods by using function.with_security_context, and the job is assigned to the user or to the user's group that ran the job.
(You cannot override the user of individual jobs if the system is configured in override mode.) The options are:
from kubernetes import client as k8s_client
security_context = k8s_client.V1SecurityContext(
run_as_user=1000,
run_as_group=3000,
)
function.with_security_context(security_context)
See the full definition of the V1SecurityContext object.
Some services do not support security context yet:
Infrastructure services
Kubeflow pipelines core services
Services created by MLRun
Kaniko, used for building images. (To avoid using Kaniko, use prebuilt images that contain all the requirements.)
Spark services