
Running a task (job)#
Learn how to submit a job using run_function, and use the RunObject to track the job and its results.
In this section
Submit tasks (jobs) using run_function#
Use the run_function() method for invoking a job over MLRun batch functions.
The run_function method accepts various parameters such as name, handler, params, inputs, schedule, etc.
Alternatively, you can pass a Task object that holds all of the
parameters plus the advanced options.
See: new_task(), and the example in run_function.
Functions can host multiple methods (handlers). You can set the default handler per function. You need to specify which handler you intend to call in the run command.
You can pass parameters (arguments) or data inputs (such as datasets, feature-vectors, models, or files) to the functions through the run method.
Parameters (
params) are meant for basic python objects that can be parsed from text without special handling. So, passingint,float,stranddict,listare all possible usingparams. MLRun takes the parameter and assigns it to the relevant handler parameter by name.
Important
Parameters that are passed to a workflow are limited to 10000 chars.
Inputs are used for passing various local or remote data objects (files, tables, models, etc.) to the function as
DataItemobjects. You can pass data objects using the inputs dictionary argument, where the dictionary keys match the function's handler argument names and the MLRun data urls are provided as the values. DataItems have many methods likelocal(download the data item's file to a local temp directory) andas_df(parse the data to apd.DataFrame). The dataItem objects handle data movement, tracking, and security in an optimal way. Read more about data items.
When a type hint is available for an argument, MLRun automatically parses the DataItem to the hinted type (when the hinted type is supported).
Use run_function as a project methods. For example:
# run the "train" function in myproject
run_results = myproject.run_function("train", inputs={"data": data_url})
The first parameter in run_function is either the function name (in the project), or a function object if you want to
use functions that you imported/created or modify a function spec, for example:
run_results = project.run_function(
fn, params={"label_column": "label"}, inputs={"data": data_url}
)
Run/simulate functions locally:
Functions can also run and be debugged locally by using the local runtime or by setting the local=True
parameter in the run() method (for batch functions).
It is supported also in Jupyter notebooks.
MLRun also supports iterative jobs that can run and track multiple child jobs (for hyperparameter tasks, AutoML, etc.). See Hyperparameter tuning optimization for details and examples.
Handlers inside a class#
You can set function handlers to methods inside a class and reference them with the
ClassName::method_name syntax. MLRun instantiates the class and then calls the named method
inside it. Instance methods, @classmethod, and @staticmethod are all supported.
# handler.py
import mlrun
class PlainClass:
def run(self, context: mlrun.MLClientCtx) -> int:
context.log_result("result", 42)
return 42
Reference the method with the ClassName::method_name handler string:
fn = project.set_function(
"handler.py",
name="my-job",
handler="PlainClass::run",
)
run = fn.run()
print(run.output("result")) # 42
Passing arguments to the constructor#
To initialize the class with custom arguments, define them in __init__ and
pass them at runtime via the special "_init_args" key inside params.
MLRun unpacks that dictionary as keyword arguments to the constructor before
calling the handler method.
If the constructor also accepts a context parameter (or **kwargs), MLRun
forwards the run context automatically alongside any _init_args you supply — useful
when you need the context available in other methods of the class beyond the handler.
# handler.py
import mlrun
class ThresholdClass:
def __init__(self, context: mlrun.MLClientCtx, threshold: float = 0.5):
context.logger.debug("Initializing the class")
self.threshold = threshold
def run(self, context: mlrun.MLClientCtx) -> None:
value = 0.9 # extract the value from the context
context.log_result("above_threshold", value > self.threshold)
Pass constructor arguments at runtime:
fn = project.set_function(
"handler.py",
name="check-threshold-job",
handler="ThresholdClass::run",
)
run = fn.run(params={"_init_args": {"threshold": 0.9}})
print(run.output("above_threshold")) # True
Async handlers#
MLRun supports async def handler functions. When a handler is defined as a coroutine,
MLRun automatically detects this and runs it to completion before committing the run result.
No code changes are required beyond adding the async keyword to the handler definition.
The ClassName::method_name syntax works with async handlers too (see the examples above).
import asyncio
import mlrun
async def fetch_data(context: mlrun.MLClientCtx) -> int:
context.logger.info("Async handler started")
await asyncio.sleep(1) # simulate async I/O
result_value = 42
context.log_result("async_result", result_value)
return result_value
Run the function exactly as you would a sync handler:
fn = project.set_function(
"handler.py", name="async-fetch-data", kind="job", image="mlrun/mlrun"
)
run = fn.run()
print(run.output("async_result")) # 42
Generators are not supported as handlers
Sync generators (def handler() with yield) and async generators (async def handler() with yield)
are not supported as MLRun job handler return types. Returning a generator raises MLRunRuntimeError
and sets the run state to error.
Run result object and UI#
The run_function() command returns an MLRun RunObject object that you can use to track the job and its results.
If you pass the parameter watch=True (default) the command blocks until the job completes.
Run object has the following methods/properties:
uid()— returns the unique ID.state()— returns the last known state.show()— shows the latest job state and data in a visual widget (with hyperlinks and hints).outputs— returns a dictionary of the run results and artifact paths.logs(watch=True)— returns the latest logs. UseWatch=Falseto disable the interactive mode in running jobs.artifact(key)— returns an artifact for the provided key (asDataItemobject).output(key)— returns a specific result or an artifact path for the provided key.wait_for_completion()— wait for async run to completerefresh()— refresh run state from the db/serviceto_dict(),to_yaml(),to_json()— converts the run object to a dictionary, YAML, or JSON format (respectively).
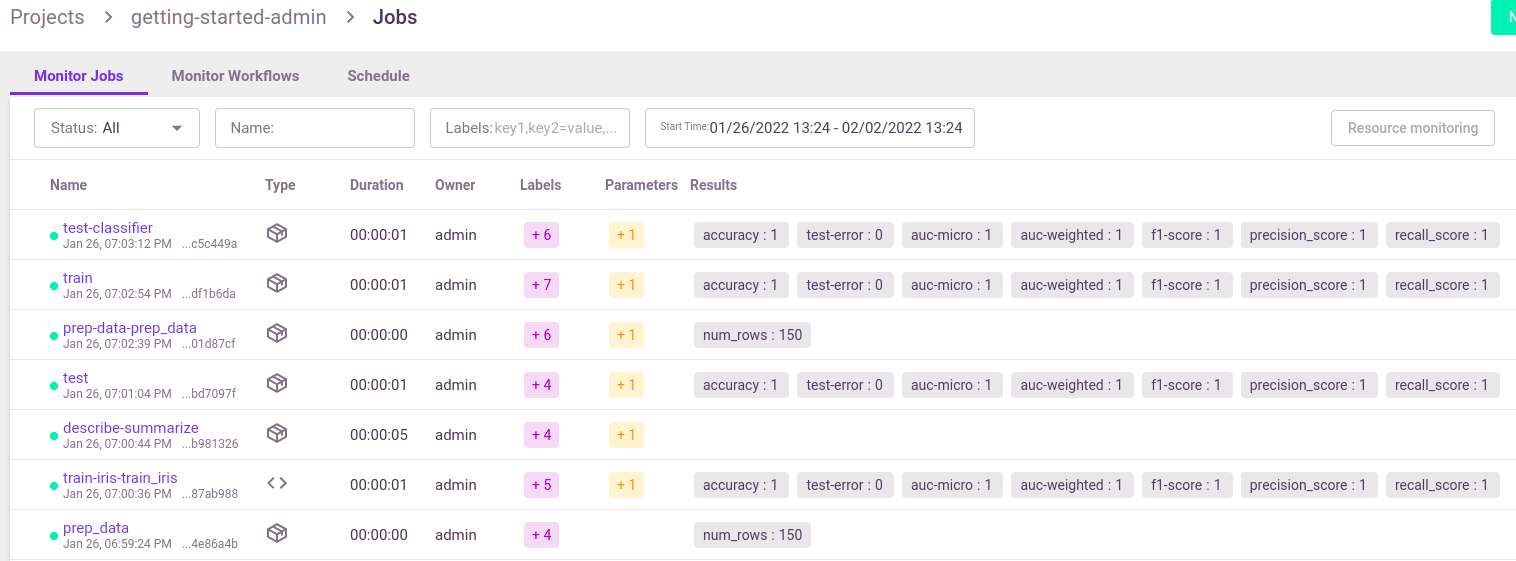
You can view the job details, logs, and artifacts in the UI. When you first open the Monitor
Jobs tab it displays the last jobs that ran and their data. Click a job name to view its run history, and click a run to view more of the
run's data.
See full details and examples in Functions.