
Change log#
The change log lists updates per version, open issues, limitations, and deprecations.
Upgrading KFP, Python, and Pydantic#
Upgrading these three MLRun dependencies spans several releases. The upgrades are comprised of:
KFP: from 1.8 to 2.x. KFP has 2 components: the KFP service, and the KFP client package (which is used in both the MLRun service and some MLRun clients) and pipeline code (which is provided by the user). The client is not yet upgraded.
Pydantic: from version 1 to 2.
See a full description of KFP, Python, and the workflow engines in Types of workflows, KFP, and Python. Specific changes are listed under the relevant versions.
v1.12.0#
Breaking Changes#
ID |
Description |
|---|---|
ML-12819 |
|
v1.11.0 (May 2026)#
Runtimes#
ID |
Description |
|---|---|
ML-5967 |
The application runtime now supports deploying from a single Python file without packaging into directories/archives; and pull-at-runtime for Git repositories or source archives. See Deploy an application from a single Python file and Pull at runtime from Git and source archives. |
ML-9209 |
MLRun supports the Kubernetes readinessProbe and livenessProbe for an application runtime sidecar. See Configure sidecar Kubernetes proble, |
ML-9754 |
You can expose multiple ports for application and Nuclio runtimes. See Expose multiple ports (application runtime) and Expose multiple ports (Nuclio). |
Serving Graph#
ID |
Description |
|---|---|
ML-7879 |
Serving graphs now support consuming messages from RabbitMQ queues and topic-based routing. See |
ML-9565 |
Serving graphs now support API handlers, used to expose endpoints and interfaces. This feature is in TechPreview status; there will be changes to the SDK in a future release. See API handler. |
ML-10258 |
MLRun can process multiple events asynchronously with HTTP triggers. Throughput is maximized, and bottlenecks are minimized. See Async mode. |
ML-10839 |
MLRun supports model serving with batched events: an invoked function is processed with an aggregated event (a single event holding multiple events), reducing GPU utilization. The trigger forwards the batch of events based on either timespan or the number of accumulated events. Both are user-configurable. See Batching, Batching example, and Serving graph with batching using a Hugging Face model. |
ML-10863 |
MLRun supports model stream responses that return tokens, rather than waiting until all the tokens are generated. This significantly reduces the latency for initial response and improves the overall user experience in gen AI workflows. See HTTP streaming step and |
ML-10753 |
MLRun supports cyclic serving graphs, used to implement agent-feedback loops. See Cyclic graph example and |
10097 |
New |
10099 |
New |
Model monitoring#
ID |
Description |
|---|---|
ML-9954 |
You can now generate an alert when lags in stream processing are detected in model monitoring writer/application pods. Lags usually indicate performance issues. See Lag detection alerts. |
ML-10919 |
Model monitoring supports TimescaleDB PostgreSQL with TimescaleDB extension as a TSDB platform. See Configuring data store profiles and |
ML-10331 |
The writer pod performance is increased by utilizing async processing. |
UI#
ID |
Description |
|---|---|
ML-1811 |
The realtime pipelines page now displays: a table of serving graphs with a few parameters that can be filtered; the total number of graphs/pipelines, the main function status, and the total number of endpoints; icons and details of the graph steps according to the step category; a model endpoints tab. |
ML-11445 |
In the Model endpoints > Metrics tab, you can now select aggregation functions, which appear as multiple lines in the values graphs. Also, you can select a period of time greater than 1 month. See Model endpoints metrics. Supported for TimescaleDB (PostgreSQL). |
Packagers#
ID |
Description |
|---|---|
ML-3474 |
MLRun now suports packagers for moving data in and out of MLRun functions by using standard Python functions with type hints and returning values. See Packagers. |
ML-11892 |
You can now get a dict of artifacts as an input. |
ML-11894 |
The user flow for changing default attributes for packagers artifacts is improved. See |
Artifacts#
ID |
Description |
|---|---|
ML-11767 |
You can now run |
Breaking Changes#
ID |
Description |
|---|---|
ML-11065 |
Python 3.9 is not supported.
|
ML-11482 |
TDEngine is deprecated. Use TimescaleDB instead. Model monitoring data in TDEngine is not migrated. |
MLRun hub#
ID |
Description |
|---|---|
10357 |
You can now import steps from the MLRun hub or your own private hub. See Load steps from the hub and |
Documentation#
ID |
Description |
|---|---|
NA |
Reorganized and updated the serving graph documentation. See Real-time serving pipelines (graphs). |
NA |
The new Profiles page describes provider profiles and source/target profiles. |
NA |
Reorganized and updated the CE installation guide. |
Closed issues#
ID |
Description |
|---|---|
ML-7955 |
The Owner field is no longer blank for artifacts that are registered in the UI. |
ML-9098 |
The date format in the date range dropdown now supports local formats. Non-supported locales use the US format: MM/DD/YYYY. |
ML-9272 |
Warning is now issued when the user supplies unexpected argument to the |
ML-9615 |
There is now a timeout to Kubernetes client operations. Previously, API workers could hang indefinitely when the Kubernetes control plane was slow or unresponsive. |
ML-10643 |
If unarchiving a project fails, there is now an error message: |
ML-11343 |
When running get_monitoring_function_summaries() without timezones now raises an error: |
ML-11354 |
The function |
ML-11382 |
RabbitMQ triggers now hides credentials in the URL. |
ML-11580 |
Previously, when creating a serving graph with steps that run in parallel and setting the graph topology engine to sync, the deployment completed but invoking the function failed since the |
ML-11581 |
Added pagination to the Alerts tab. Now when opening the Alerts tab when there are numerous alerts, the message is |
ML-11780 |
Fixed the error in Model monitoring tutorial that resulted in failure of |
ML-11820 |
Improved the time to access the monitoring page (V3IO). |
ML-11969 |
Fixed description of alert auto reset that alerts are reset immediately. See Alert reset policy. |
ML-11985 |
Improved the error message when a step of any kind is created with |
ML-12311 |
Resolved issue of failure to return project workflows by changing the defaults: counter refresh time is 1 mninute (was 30 seconds); and "in progress workflow counters" count only the last 2 days. |
ML-12328 |
Fixed KFP experiments pagination. |
ML-12372 |
Fixed workflows pagination. |
v1.10.3#
Closed issues#
ID |
Description |
|---|---|
ML-12379 |
Fixed workflows pagination. |
v1.10.2 (February 2025)#
Important
v1.10.x are the last versions that support Python 3.9 and TDEngine. They will not be supported in MLRun v1.11.0.
TDEngine will be replaced with TimescaleDB. Model monitoring data in TDEngine will not be migrated.
Closed issues#
ID |
Description |
|---|---|
ML-11771 |
Resolved issue of Users temporarily unable to access projects by improving all the async clients to use per-thread session instances and all http clients to use a dummy cookie jar. |
v1.10.1 (January 2026)#
Closed issues#
ID |
Description |
|---|---|
ML-10488 |
Validation of mail configuration does not fail on non-required parameters. See the updated documentation Mail notifications. |
ML-11277 |
Increased the performance of reading partitioned parquets, thereby preventing lag in processing the model monitoring events. |
ML-11383 |
Monitoring app UI: The Kind column in the Results tab now prints the description, and not the value as previously. |
ML-11400 |
When deploying a serving function as a job, the artifact is now as expected. |
ML-11408 |
After an app runtime reached |
ML-11517 |
Resolved the thread-safety issues that occasionally caused failure during invoke time when serving using 2 Hugging Face models with |
ML-11530 |
Model monitoring appplications that have underscores in their names no longer causebreakage when trying to view the counters from the Project view. Underscores in function names will be deprecated in v1.11.0. See Upcoming changes. |
ML-11545 |
Running a workflow with Jupyter on Iguazio systems, the pipeline UI link now resolves successfully. |
ML-11597 |
The Model monitoring tutorial now runs successfully. Previously it failed with an error "NameError: name 'alert_objects' is not defined". |
ML-11602 |
In a Python 3.9 environment on Dask clusters, when running code that specifies the |
ML-11791 |
Documentation: Clarified project.save() and function.save(): functions are not saved when you save your project, and how to save functions to the DB. See A word about saving functions. |
NA |
Security fixes. |
v1.10.0 (November 2025)#
MLRun hub#
ID |
Description |
|---|---|
ML-9564 |
You can now import monitoring apps from the MLRun hub or your own private hub. See import a model monitoring application. |
ML-9319 |
You can now import python modules from the MLRun hub or your own private hub. See import a module. |
Serving#
ID |
Description |
|---|---|
ML-9685 |
You can now use models stored in a remote source like HuggingFace, without saving it in your datastore. See Remote models and Serving using a remote model. |
ML-9642 |
The new ModelRunnerStep enables running a model as part of a inference graph. It gives you an advanced way to run multiple models with control over how they are executed in terms of concurrency and parallelism. See ModelRunnerStep and |
Artifacts#
ID |
Description |
|---|---|
ML-9812 |
This version introduces LLM prompt templates and artifacts and experiment tracking on artifacts. You simply use your selected provider (e.g., OpenAI or Hugging Face). See Using LLM prompt templates and artifacts, Gen AI realtime serving graph, and LLM prompt artifacts. |
Model Monitoring#
ID |
Description |
|---|---|
ML-9577, ML-4309 |
You can run model monitoring on the new ModelRunnerStep. See the example in Using LLM prompt templates and artifacts. |
ML-9613 |
The new Monitoring Application view, accessed with the Monitoring app icon in the menu, provides you with a comprehensive overview of your model monitoring applications and their status. See View the model monitoring applications status in the UI. |
ML-8072 |
You can now run a model monitoring application as a batch application on existing model endpoint data. See Running the model monitoring application. |
Batch run#
ID |
Description |
|---|---|
ML-5986 |
You can now use the SDK to configure retries on runs that fail. See run_function. |
ML-9681 |
You can now deploy a serving graph as a job. See Batch inference and drift detection. |
UI#
ID |
Description |
|---|---|
ML-9351 |
You can now terminate a workflow from the UI with either the Terminate button or the Terminate option in the vertical ellipsis menu, depending on the page you are in. |
ML-9430 |
The cross-project and Project monitoring views have two new tiles: Artifacts (in sub-categories: Datasets, Documents, LLM pompt artifacts, Other artifacts) and Models. The Project page has an additional tile: Applications. The project monitoring page now display Runs instead of Jobs, and the "Scheduled" counter estimates upcoming runs. Consumer groups is now located under Real-Time and ML functions. |
Breaking Changes#
ID |
Description |
|---|---|
ML-10279 |
The default project ( |
Infrastructure#
ID |
Description |
|---|---|
ML-2714 |
MLRun supports Confluent Kafka 7.8. |
ML-7770 |
You can now change the context logger format. |
ML-10799 |
When using the KFP client, you can now use Kubeflow Pipelines (KFP) 1.8.23, which supports Python 3.11. |
Upcoming changes#
ID |
Description |
|---|---|
NA |
The default |
ML-11414 |
Use of underscore '_' in function names will be deprecated in an upcoming release. Use dashes '-' instead. |
Documentation#
ID |
Description |
|---|---|
NA |
New tutorial: Using LLM prompt templates and artifacts. |
NA |
New page: Model serving steps. |
NA |
New page: Running the model monitoring application. |
NA |
New page: View the model monitoring applications status in the UI. |
NA |
New page: LLM prompt artifacts. |
NA |
New page: Integrating an OpenAI LLM with MLRun. |
NA |
New section: Remote models. |
NA |
New section: Serving using a remote model. |
NA |
Updated page: MLRun hub. |
NA |
Updated with new functionality: Gen AI realtime serving graph |
NA |
Improved the Real-time serving pipelines (graphs) documentation. |
ML-7770 |
New section: Configuring custom loggers |
ML-8094 |
Added use cases and syntax for the |
ML-10676 |
Fixed CE installation pages: Install MLRun CE on AWS and Install MLRun CE on Kubernetes. |
Closed issues#
ID |
Description |
|---|---|
ML-7678 |
Warning is raised when |
ML-7771 |
Updated message when user tries to create a project but does not have developer permission: "Permission denied: Unable to create a project. Contact your system administrator to review user policy and data access permissions." |
ML-8549 |
Documentation: Clarification that email notification isn't sent for local jobs unless the default email SMTP settings are explicitly set. See Local vs. Remote. |
ML-8601 |
Default spot labels node selector are no longer removed. |
ML-8674 |
Notifications are now issued when retrying pipelines. |
ML-8756 |
When assigning a node selector from the list of |
ML-9338 |
|
ML-9452 |
A monitored serving function deploy will fail early on validation if model monitoring credentials were not set. Previously, it failed later in the build stage. |
ML-9508 |
You can now load code from python file from git/http using |
ML-9550 |
Deleting projects with many artifacts now does not fail. Previously failed due to the artufacts. |
ML-9573 |
Adds a shared Kubernetes client with built-in retries to make CoreV1Api and CustomObjectsApi calls more reliable during temporary API hiccups. |
ML-9725 |
Fixed the correct number of replicas in the serving function spec. |
ML-9752 |
You can now use |
ML-9848 |
Fixed "TypeError: init() got an unexpected keyword argument 'details'" upon ingestion to DBFS. |
ML-9869 |
UI: Fixed issue when "Artifacts" icon in navigation bar was not clickable when custom filter enabled. |
ML-9876 |
Resolved issue of DB probes failing when the concurrent connections are maxed out. |
ML-9884 |
UI: After modifying a schedule the UI now remains on the Scheduled page. Previously it redirected to the specific project schedules. |
ML-9899 |
Compressed workflow size limitation exceeded resolved by documentation update: do not use |
ML-9911 |
Using the same tag across different artifacts is now allowed. |
ML-9937 |
UI: When clicking on the UID link after running a job in Jupyter, the Job run page opens. Previously, the project page opened. |
ML-9971 |
UI: When registering an artifact, you can reselect an option in the Target path and the dropdown closes. Previously the option was not selected and the drop-down remained open. |
ML-10289 |
When using the |
ML-10293 |
Scheduled workflow jobs now use the values in the |
ML-10349 |
You can now use two different S3 credentials for source and target. |
ML-10411 |
|
ML-10422 |
Calling |
ML-10612 |
The |
ML-10622 |
The remote and schedule workflow owner labels now show the username. |
ML-10665 |
Monitoring>Workflows now shows the correct number of workflows. Previously it occasionally reported 0. |
ML-10924 |
UI: The input_path and result_path of steps now display in "Real-time pipelines". |
ML-10952 |
UI: In the Jobs page, Batch run, the current project now appears in the Function dropdown. |
ML-10987 |
UI: Resolved the issue of displaying Workflows in the Monitor workflows page with KFP 2.5. |
v1.9.2 (July 2025)#
Closed issues#
ID |
Description |
|---|---|
ML-10147 |
Fixed the image build process, thereby resolving issues with the tutorial Model monitoring using LLM. |
ML-10296 |
Now, when using |
ML-10358/10359 |
MLRun now supports TensorFlow up to 2.19.0. |
NA |
Security fixes. |
Documentation#
ID |
Description |
|---|---|
NA |
Workflow engine types and the interdependencies with Python are fully described in Types of workflows, KFP, and Python. |
ML-10367 |
Improved the description of creating an alert, including |
v1.9.1 (June 2025)#
Breaking change#
ID |
Description |
|---|---|
NA |
The project default image no longer affects the workflow runner image. |
Closed issue#
ID |
Description |
|---|---|
ML-10326 |
Fixed the image tag extraction process. |
v1.9.0 (June 2025)#
Infrastructure#
ID |
Description |
|---|---|
ML-9326 |
MLRun now supports Python 3.11, and also continues to support Python 3.9. Workflows that use Python 3.11 must use |
ML-10199 |
KFP 2.x server is now supported, but workflows still require the KFP 1.8 syntax. Usage guidelines:
|
Breaking change#
ID |
Description |
|---|---|
ML-10186 |
By default, the remote workflow runs with the mlrun/mlrun-kfp image that includes the KFP Python package. If you want to use a different image to compile your workflow, you must install kfp~=1.8, use Python 3,9, and you can change the image by using |
Closed issues#
ID |
Description |
|---|---|
ML-4767 |
PyTorch 2.1.0 is now compatible with |
ML-9894 |
Logging artifacts to the V3IO store does not result in an "EOF occurred in violation of protocol" error. |
Model monitoring#
Important
You must use the v1.8.0 client or higher to utilize model monitoring on a v1.9.0 server.
v1.8.0 (June 2025)#
Model monitoring#
ID |
Description |
|---|---|
ML-9305 |
Model monitoring is now GA. It requires Nuclio>=1.13.12. It is not backwards-compatible with previous versions. See Upgrading the MLRun server if model monitoring is deployed in v1.7.x. |
ML-7731 |
Model monitoring can now be run on a larger scale, using MLRun's additional replicas/workers. |
ML-8281 |
MLRun now supports experiment tracking for document-based models, integrating management of LangChain documents using the new artifact type |
ML-8537 |
You can now run and evaluate models before deploying them, saving time and resources. See Testing your application before deploying it. |
ML-7688 |
You can now give model endpoints a name of your choice. |
The SDK for creating model monitoring alerts is much simpler than previously. See Create a model monitoring alert. |
Upgrading the MLRun server if model monitoring is deployed in v1.7.x#
To upgrade the MLRun server:
Before upgrading:
Optionally redeploy all monitored serving functions with
set_tracking(False). Otherwise, upgrade the image serving function to mlrun==1.8.0 before the deployment (with tracked functions).Run
project.disable_model_monitoring(delete_stream_function=True, delete_user_applications=True). This removes all MM applications, infra pods, and the streams.
After upgrading, start using model monitoring as usual. See Model monitoring tutorial.
Notes
Model monitoring is disabled on your project after the upgrade; all the functions deploy without tracking and all the model monitoring applications were deleted.
You must use the v1.8.0 client to utilize model monitoring on a v1.8.0 server.
Alerts#
ID |
Description |
|---|---|
ML-7870 |
Alerts are now enabled by default. |
ML-8472 |
You can now list the alert activation history and filter the list by various parameters using the SDK. See Listing alert activations. |
Notifications#
ID |
Description |
|---|---|
ML-5985 |
You can now send notifications by email. See Mail notifications. |
Runtimes#
ID |
Description |
|---|---|
ML-8642 |
|
Breaking changes#
ID |
Description |
|---|---|
ML-8951 |
Evidently-related code is now in a dedicated module. Code that imported |
Model monitoring credentials are now part of the project. See Import, enable monitoring, and deploy the serving function. |
Infrastructure#
ID |
Description |
|---|---|
ML-8314 |
KFP is no longer part of the MLRun images, except for the new |
NA |
MLRun supports Pydantic 2. |
UI#
ID |
Description |
|---|---|
ML-8120 |
The main counters in the Projects page are now clickable, replacing the "See all" links. |
ML-8276 |
You can now retry a workflow in the UI. The retry maintains the same experiment ID and just re-runs it, without changing anything in the workflow spec or code. The retry option is in enable in the 3-dots menu for the pipeline. |
ML-8346 |
The cross-project view now shows the number of alert activations within the project. From there you can drill down per endpoint, jobs, and application.
|
ML-8352 |
Queries are now implemented with pagination, increasing responsiveness and reducing resource requirements. |
ML-7824 |
The Jobs and Workflow>Monitor Workflows and Schedule panes now have a pop-up filter, and the Batch Run button is in the same row — providing more space for the lists in the tables. |
ML-7825 |
The Feature Store panes now have a pop-up filter, and the Create Set/Vector button is in the same row — providing more space for the lists in the tables. |

Documentation#
ID |
Description |
|---|---|
ML-6379 |
New tutorial: Experiment tracking with a vector DB. |
NA |
New page: Types of workflows, KFP, and Python. |
Closed issues#
ID |
Description |
|---|---|
ML-4168 |
If a |
ML-6826 |
The improved error message for a non-scheduled pod, for example preempted, is now: A Kubernetes pod related to this run cannot be found, possibly it was preempted or evicted. Additional details may be available from Kubernetes events. |
ML-7270 |
Retrieving artifacts with |
ML-7347 |
Model monitoring aplication: Logging artifacts does not leak memory. (The artifact manager no longer saves each logged artifact.) |
ML-7384 |
New label validation for all of the list methods in the SDK, including |
ML-7905 |
When changing the Docker Registry, MLRun now uses the correct secrets on redploy of the function. |
ML-8060/9 |
Notifications are now sent by the workflow, and not by the client as previously. |
ML-8064 |
Notifications with |
ML-8107 |
The column widths of Name and Value in the Job results page are now allocated appropriately. |
ML-8115 |
Deploying a model without monitoring now creates an endpoint. |
ML-8273 |
Resolved issue of mlrun worker occasionally not able to connect to chief. |
ML-8331 |
Non-root users can now build images when the source is stored in a zipped file. |
ML-8571 |
Jobs/runs executed in a workflow with artifacts with |
ML-8949 |
Only one artifact is tagged as latest, resolving the MultipleResultsFound error. |
ML-9155 |
The improved performance reduces timeouts that cause restart of MLRun workers. |
ML-9201 |
Running |
ML-9257 |
Model monitoring: A mismatch between the serving function response and the MEP expected output is saved correctly (and does not cause the application to fail). |
ML-9321/9432 |
Notifications no longer get stuck in "Pending" in the DB. |
ML-9341 |
Increased the limit of alert configurations on the system up to 20k (from 10k). |
v1.7.x#
v1.7.2 (16 January 2025)#
Closed issues#
ID |
Description |
|---|---|
ML-8841 |
Application runtimes no longer duplicate the configured resources for the running pod. |
ML-8842 |
Failed pipelines now send notifications when using webhook. |
ML-8892 |
UI: Artifact counters now display correctly. |
ML-8974 |
UI: Artifacts stored as S3 now display in the UI. |
ML-9053 |
Fixed the race condition when updating artifacts with the same key. |
v1.7.1 (2 December 2024)#
Serving graph#
ID |
Description |
|---|---|
ML-7818 |
Serving graphs can now use a conditional step. |
Breaking changes#
ID |
Description |
|---|---|
ML-7801 |
When running a remote/scheduled workflow, the remote workflow pulls/extracts the remote source content to the running pod but loads the project configuration from the MLRun DB and not from the |
Closed issues#
ID |
Description |
|---|---|
ML-7285 |
Improved the response time when loading the Feature sets page. |
ML-7967 |
Fixed the |
ML-8001 |
Job failures are now described in the job details and when hovering over the status (in the Projects > Jobs monitoring > Jobs page). |
ML-8006 |
Fixed the pipelines error message for a failed step (previously included messages from other (skipped) steps of the workflow). |
ML-8012 |
You can now use the same tag on more than one model. |
ML-8046 |
The number of TSDB records is now correct when running model monitoring with a user app. |
ML-8080 |
Projects with many artifact tags can now be deleted without complications. |
ML-8082 / 8246 |
You can now delete projects with large number of resources in TDEngine. |
ML-8097 |
UI: Now displays the pod status in Monitor Jobs when you hover over the status symbol. |
ML-8110 |
Fixed the scheduled jobs counters in the project summary. |
ML-8112 |
Logging a model with a training set that has large number of columns now displays the model feature statistics. |
ML-8150 |
Fixed the 03-model-serving tutorial so that all tutorials can be run sequentially. |
ML-8151 |
Fixed the error message that displays when deploying monitoring without setting the required credentials. |
ML-8171 |
The Projects page does not refresh every time you click in the Search box (the previous behavior). |
ML-8195 |
You can now use |
ML-8215 |
You can now use an asterisk ( "*") in the project name parameter of |
ML-8217 |
The counters in the Projects page now have tooltips. |
ML-8224 |
Kafka topics are now deleted together with the project during project deletion. |
ML-8286 |
The tooltip for failed jobs now differentiates between Error and Reason. |
v1.7.0 (1 November 2024)#
Model monitoring#
Note
Model monitoring is in TechPreview.
ID |
Description |
|---|---|
ML-5459 |
Improved support for unstructured data handling, including for LLMs. |
ML-5460 |
The model monitoring now has a per-endpoint view that presents information data on the monitoring metrics. |
ML-5851 |
Model monitoring supports Kafka or V3IO as streaming platforms, and TDEngine or V3IO as TSDB platforms. See Selecting the streaming and TSDB platforms. |
Alerts#
ID |
Description |
|---|---|
ML-5287 |
You can now configure alerts for model monitoring and other possible problem situations. TechPreview. |
Projects#
ID |
Description |
|---|---|
ML-3874 |
Node selector can now be defined in the project spec. |
Artifacts#
ID |
Description |
|---|---|
ML-2585 |
When deleting a artifact, you can also delete the data of a single artifact. |
Runtimes#
ID |
Description |
|---|---|
ML-2652 |
|
ML-4601 |
New application runtime where you can provide an image (for example, a web-app) that runs as a Kubernetes deployment. |
Workflows#
ID |
Description |
|---|---|
ML-6885 |
You can now add run details to the notification by using |
Functions#
ID |
Description |
|---|---|
ML-4248 |
You can now load models from a json file instead of adding all the models to the function spec. |
Serving graph#
ID |
Description |
|---|---|
ML-6015 |
Storey/Nuclio serving graph: supports concurrent processing, typically used for serving of deep-learning models, where preparation steps and inference can be CPU/GPU heavy, or involving I/O. |
Data store#
ID |
Description |
|---|---|
ML-5726 |
Add support for Hadoop/hdfs datastore. |
Notifications#
ID |
Description |
|---|---|
ML-6644 |
Explicit control of the configuration for the Pipeline started notification. |
Breaking changes#
ID |
Description |
|---|---|
ML-5741/3206 |
The new flag |
Feature store#
ID |
Description |
|---|---|
ML-3303 |
Optimized the parquet read when the partitioning is on fields other than the timestamp. |
ML-5656 |
UI#
ID |
Description |
|---|---|
ML-4666 |
The new cross-project view gives a summary of all jobs, workflows, and schedules that ran in the last 24 hours.
|
ML-5140 |
Improved responsiveness for runs and functions. |
ML-5846 |
The Filter in the Projects>ML Functions table is now a popup menu. |
ML-6275 |
The Projects dashboard now notifies when MLRun isn't reachable. |

Documentation#
ID |
Description |
|---|---|
ML-6052 |
New page: Logging artifacts. |
ML-7480 |
New note: ARM64 (Apple Silicon) Users and Python 3.9. |
ML-7669 |
New topic: Setting the log level. |
NA |
New tutorial: Model monitoring using LLM. |
NA |
New page: Writing a model monitoring application. |
NA |
Updated page: Model monitoring architecture. |
NA |
Updated MLRun ecosystem. |
Closed issues#
ID |
Description |
|---|---|
ML-2223 |
Can now deploy a function when notebook names contain "." |
ML-3143/ML-3432 |
Can now delete remote (Nuclio) functions from the DB with both the SDK and the UI. |
ML-3680 |
Function specs that are modified before running the workflow are now saved. |
ML-3804 |
A serving step with no class now inherits parameters from the function spec. |
ML-4442 |
You can now add monitoring after a model is deployed ( |
ML-4490 |
Documentation: Added caveat that MLRun does not support decompressing large Kubeflow pipeline graphs. |
ML-4636 |
A local run that was created via |
ML-4846 |
CE: |
ML-4934 |
Modifying the parameters of a serving-function (for example changing |
ML-5079 |
You can now update git remote with |
ML-5204 |
UI: The Project settings now provide validation rules on labels. |
ML-5627 |
Documentation: Added details about |
ML-5774 |
UI: Improved speed of querying for pipelines of specific projects in the Pipelines page. |
ML-6020 |
UI: Copy URI in the Datasets main page now copies the same value as in the detailed Dataset page. |
ML-6065 |
Fixed serving graphs when working with Kafka. |
ML-6068 |
Feature-store Redis-target is now created by default with the project/feature-set in the path. |
ML-6194 |
When running a remote workflow, the client side does not need to contain workflow local files. |
ML-6249 |
Reduced the time that feature sets with a large number of entities take to query (and no longer timeout). |
ML-6253 |
The |
ML-6602/6556 |
You can now specify a UID when running |
ML-6800 |
Resolved spiking of CPU and memory of mlrun-api service. |
ML-6991 |
UI: Now shows KFP pod errors. |
ML-7103/7131 |
UI: By default the UI only retrieves tagged functions: non-tagged functions are only retrieved if explicitly asked for. Added time filters to the Functions page, by default shows only functions that were modified in the last week. The changes improve the overall responsiveness. |
ML-7119 |
When attempting to create a project without the required permissions, the error now reads: You don’t have permission to create a project. |
ML-7135 |
Fixed upgrading mlrun if the |
ML-7162 |
UI: Erroneous "“No data matches…” messages no longer appear. |
ML-7192 |
Improved the liveness and readiness probes responsiveness. |
ML-7202 |
The run state now indicates if a pod failed on OOM. |
ML-7226 |
Exception now raised when using use KFP engine with |
ML-7232 |
The run state now indicates when a pod fails on OOM. |
ML-7256 |
Deleting artifact by UID deletes only the artifact with the given UID. |
ML-7290 |
Nuclio functions deployed by MLRun: At the Nuclio service level, node selectors are added by Nuclio. In cases where there is overlap between the node selectors specified at the MLRun service level and those applied by Nuclio, the node selectors from the MLRun side take precedence to prevent any conflicts. See node selection. |
ML-7335 |
Serving functions now support up to 4500 models and the size of the serving specification to 1 MB. |
ML-7358 |
MLRun client now validates SSL certificates by default. |
ML-7367 |
Updated OS packages for MLRun UI. |
ML-7404/7405 |
Documentation: Added the minimum Nuclio version for supporting |
ML-7416 |
An error message is now displayed upon workflow failure in the "Monitor workflows" tab. |
ML-7599 |
Fixed mlrun-api vulnerabilities. |
ML-7613 |
The pipeline SDK output now displays the logs in addition to the graph animation, and it also raises a warning when a client uses notifications with |
ML-7655 |
The "filter by label" in the Models page is now case insensitive. |
ML-7673 |
Improved performance of |
ML-7674 |
Modified MLClientCtx.log_level() to change the context logger log level |
ML-7706 |
Changed |
ML-7796 |
New |
ML-7907 |
Fixed an issue with RabbitMQ event path when using Model serving functions. |
ML-8027 |
Fix periodic log collection to list only runs with pods. |
ML-8029 |
Notifications with secret params now send notifications. See Notification parameters and secrets. |
v1.6.x#
v1.6.4 (2 July 2024)#
UI#
ID |
Description |
|---|---|
ML-6867 |
Scalability improvement. The artifacts page (artifacts/datasets/models) now displays a maximum of 1000 items. (Use filters to focus the results.) |
Closed issues#
ID |
Description |
|---|---|
ML-6770 |
Resolved MLRun workers restart when running many workflows that produce artifacts. |
ML-6795 |
Can now upgrade to v1.6.4 when cluster has artifacts that do not have a |
v1.6.3 (4 June 2024)#
Workflows#
ID |
Description |
|---|---|
ML-3521,5482 |
Remote/scheduled workflows can now be performed by a project with a source that is contained on the image. See Scheduling a workflow. Tech Preview. |
Infrastructure#
ID |
Description |
|---|---|
ML-5739 |
MLRun now supports email-like username. |
Documentation#
ID |
Description |
|---|---|
ML-4620 |
Updated Realtime monitoring and drift detection tutorial and Model monitoring for the model monitoring feature introduced in v1.6.0. |
NA |
New Deploying an LLM using MLRun tutorial. |
NA |
New sections describing gen AI tasks: Gen AI development workflow, Gen AI data management, Developing a gen AI pipeline, Deploying gen AI application serving pipelines. |
NA |
New page describing Logging artifacts. |
NA |
New page describing Running a workflow with multiple functions in parallel. |
NA |
New page describing Running a conditional workflow. |
NA |
New page describing Running a multiple function workflow with ExitHandler. |
Breaking change#
ID |
Description |
|---|---|
ML-6098 |
The |
Closed issues#
ID |
Description |
|---|---|
ML-4149 |
UI: Workflows are now listed from newest to oldest. |
ML-5763 |
The log formatter options can now be changed by an env var. |
ML-5772 |
Resolved: "Projects" screen/counters may show "N/A" or "MySQL server has gone away" transient error. |
ML-5776 |
Concurrent request to project deletion now do not fail. |
ML-6000 |
Improved MLRun startup time on system with large number of runs. |
ML-6026 |
Remote workflows using a large image no longer time-out. |
ML-6045 |
UI: User-filters return all of the matching users. |
ML-6048 |
UI: An admin user can now change its role in the project. |
ML-6051 |
UI: After an admin user deletes itself from a project, the user is redirected. |
ML-6188 |
If a workflow runner pod fails due to an application error, an immediate response returns the error (and not that the workflow does not exist). |
ML-6194 |
When running workflows with a remote engine, functions files are not synced instead they are loaded dynamically during runtime. |
ML-6317 |
Reduced MLRun memory consumption. |
ML-6384 |
Improved resource consumption of list runs with partitioning query |
ML-6397 |
Artifacts are no longer stored in the run body in the DB, instead a map of artifact keys to URIs is maintained. |
ML-6489 |
Resolved jobs transient failures with error 'ClientOSError(104, 'Connection reset by peer')'. |
v1.6.2 (29 March 2024)#
Closed issues#
ID |
Description |
|---|---|
ML-4758 |
Heavy projects can be deleted successfully. |
ML-5808 |
Fix selecting the project-owner user. |
ML-5907 |
"Invite New Members" now returns the full list of users when there are 100+ users in system. |
ML-5749, 6037 |
After the user removes ownership of the currently displayed project, the UI redirects to the Projects page. |
ML-5977 |
The 'Members' tab in Project settings is now shown for groups with admin privileges. |
v1.6.1 (29 February 2024)#
Closed issue#
ID |
Description |
|---|---|
ML-5799 |
The artifact |
v1.6.0 (22 February 2024)#
Data store#
ID |
Description |
|---|---|
ML-3618 |
Integrate MLflow: seamlessly integrate and transfer logs from MLflow to MLRun. Tech Preview. |
ML-4343 |
Datastore profiles (for managing datastore credentials) now support Azure, DBFS, GCS, Kafka, and S3. See Using datastore profiles. |
Feature store#
ID |
Description |
|---|---|
ML-4622 |
Feature set and feature vector APIs are now class methods. See examples in Feature sets and Feature vectors. |
ML-5109 |
You can set |
Model monitoring#
ID |
Description |
|---|---|
ML-4620 |
Model monitoring is now based on monitoring apps that are run on a set of model end-points, see Model monitoring. The Grafana Model Monitoring Applications dashboard now includes charts and KPIs that are relevant to a specific monitoring application (under a specific model endpoint). The graphs are: Draft status by category, Average drift value result, Latest result, Application summary, Result value by time, Drift detection history. See Model Monitoring Applications dashboard. |
Runtimes#
ID |
Description |
|---|---|
ML-3379,4997 |
New |
ML-3728 |
Labels added to pods that are running as part of KFP to facilitate monitoring. View in Git. |
ML-4032 |
You can now disable the automatic HTTP trigger creation in Nuclio and MLRun. See Serving/Nuclio triggers. |
ML-4182 |
Support for notifications on remote pipelines. See Configuring Notifications For Pipelines. |
ML-4623 |
You can now Log a Databricks response as an artifact. |
UI#
ID |
Description |
|---|---|
ML-1855 |
New Train Model wizard. |
ML-2336 |
You can now delete Jobs in the UI (and not just from the SDK). |
ML-4506 |
You can now delete artifacts, models, and datasets in the UI (and not just from the SDK). |
ML-4667 |
Project monitoring is now the default project view. The previous default page is now named Quick actions, and is the second tab in the Projects page. |
ML-4916 |
You can now add a tag when registering an artifact in the Register Artifact, Register Dataset, and Register Model dialogs. |
Infrastructure#
ID |
Description |
|---|---|
ML-3921 |
The Docker image for installation of mlrun was modified, resulting in better compatibility with external packages. |
ML-5193 |
Support for Pandas 2.0. |
Documentation#
ID |
Description |
|---|---|
ML-3663 |
New: How to build a docker image externally using a Dockerfile and then use it. See Building a docker image using a Dockerfile and then using it. |
ML-4048 |
New: Creating and using a custom function hub. See Custom hub. |
ML-5260 |
|
ML-5602, ML-5680 |
Improved feature store documentation including sources and targets, and partitioning. See Sources and targets. |
NA |
|
NA |
Improved serving function example, and new example of a serving function with Git integration. See Function of type serving. |
Breaking Changes#
ID |
Description |
|---|---|
ML-4741 |
The default |
Closed issues#
ID |
Description |
|---|---|
ML-76 |
Artifacts submitted from a git based project can now be received (after changing the HEAD git commit of the project between different log_artifact calls) . |
ML-1373 |
Incorrect service names do not result in stuck pods during ContainerCreating. |
ML-1835 |
The index record is not duplicated in the datasets metadata. |
ML-3714 |
Runs that complete successfully do not show errors in Kubeflow. |
ML-3856 |
Documentation: Add how to update a feature set with appending ingestion (and not create a new FS on every ingest). See Ingest data locally. |
ML-4093 |
Documentation: Improved description of handlers and Functions. |
ML-4370 |
Hyper-param and single runs no longer generate artifacts with the same name. |
ML-4563 |
Local jobs can now be aborted in the UI. |
ML-4585 |
The |
ML-4613 |
UI: Fixed the map type hint in the Batch Inference Parameters. |
ML-4642 |
The UI no longer gets stuck when there is a high number of query results. |
ML-4678 |
When tagging a specific version of a model using the SDK, it does not clear the tags from the rest of the versions. |
ML-4690 |
Enabling the Spark event log (sj.spec.spark_conf["spark.eventLog.enabled"] = True) no longer causes the job to fail. |
ML-4920 |
Documentation: improve description of |
ML-4608 |
The artifact |
ML-4617 |
Fixed error message when using a feature vector as an input to a job without first calling |
ML-4714 |
Logs are not truncated in the MLRun UI logs page for jobs that have a high number of logs or run for over day. |
ML-4810 |
Can now rerun a job when the "mlrun/client_version" label has "+" in its value. |
ML-4821 |
Very big projects are deleted successfully. |
ML-4855 |
MLRun now supports TensorFlow up to 2.15.0. |
ML-4857 |
When local runs are aborted in the UI, the actual execution is also aborted. |
ML-4858 |
After aborting a job/run from the UI, the logs are populated. |
ML-4922 |
Preview and Metadata tabs now indicate when there are more columns that are not displayed. |
ML-4967 |
The Deploy button in the Project > Models page now creates a new endpoint/serving function. |
ML-4992 |
Fixed starting a spark job from source archive (using |
ML-5001 |
The Monitoring workflows page now states that it includes only workflows that have already been run. |
ML-5042 |
After creating and deleting a project, a new project cannot be created in the same folder with the same context. |
ML-5048 |
UI Edit function dialog: When selecting Use an existing image and pressing Deploy, the existing image is used, as expected. |
ML-5078 |
|
ML-5089 |
When trying to delete a running job, an error opens that a running job cannot be deleted and it needs to be aborted first. |
ML-5091 |
Monitoring does not recreate a deleted run. |
ML-5146 |
Resolved OOM issues by reducing the memory footprint when monitoring runs. |
ML-5175 |
For Nuclio runtimes, MLRun is now installed together with user requirements, to account for MLRun dependencies. |
ML-5481 |
You can now use |
ML-5576 |
FeatureSet can now ingest data that contains single quotes. |
ML-5746 |
Labels no longer create partial projects that cannot be deleted. |
v1.5.x#
v1.5.2 (30 November 2023)#
Closed issues#
ID |
Description |
|---|---|
ML-4960 |
Fixed browser caching so the Members tab is always presented for projects. |
v1.5.1 (2 November 2023)#
Closed issues#
ID |
Description |
|---|---|
ML-3480 |
Add details about |
ML-4839/4844 |
Running |
ML-4860 |
Fixed creating and running functions with no parameters from the UI. |
ML-4872 |
Fixed synchronizing functions from project yaml. |
v1.5.0 (23 October 2023)#
Data store#
ID |
Description |
|---|---|
ML-2296 |
Add ability to manage Redis datastore credentials with datastore profiles. See Using datastore profiles, view in Git. |
ML-3500 |
Support for DBFS data store (Databricks file system). See Databricks file system, view in Git. |
Feature store#
ID |
Description |
|---|---|
ML-3784 |
Support for feature vector-defined feature-set relations and join-type (per-join). Tech Preview. See Feature vector with different entities and complex joins and view in Git. |
Infrastructure#
ID |
Description |
|---|---|
ML-3370 |
Accessing the MLRun hub is now available through a service API. This will enable implementing better function version selection and combining hub functions from different sources. Tech Preview. View in Git. |
ML-3644 |
Support for self-signed docker registries. See Using self-signed registry and view in Git. |
ML-4132 |
The |
NA |
From v1.5, clients must be running Python 3.9. |
Runtimes#
ID |
Description |
|---|---|
ML-3501 |
Support for running Spark jobs on Databricks cluster. See Databricks. View in Git. |
ML-3854 |
Support for webhook notification. See webhook in Notifications and view in Git. |
ML-4059 |
Support for adding env vars or secrets to the docker build during runtime. See Extra arguments, |
UI#
ID |
Description |
|---|---|
ML-2811 |
New Batch Inference wizard. Tech Preview. |
ML-2815 |
New Batch Run wizard that replaces the previous New job page. |
ML-3584 |
The Model Endpoints page now displays the Function Tag. |
ML-4066 |
The Online types list of the Target Store now includes Redis. |
ML-4167 |
The Projects page now supports downloading the .yaml file. Tech Preview. |
ML-4571 |
The Model Endpoints page now displays the drift threshold and the drift actual value. |
ML-4756 |
The Recents list in Jobs and Workflows (Projects pane) now displays a maximum of the last 48 hours. |
ML-4511 |
You can now change the image and add new requirements (such as |
Documentation#
ID |
Description |
|---|---|
ML-3763 |
Add description of configuring number of workers per GPU. See updated Number of workers/GPUs. |
ML-4420 |
Add configuration of memory in Spark Operator. See Spark Operator runtime. |
ML-2380 |
Add details of V3IO and Spark runtime. See Spark Operator runtime and |
Breaking changes#
ID |
Description |
|---|---|
ML-3823 |
The default format of |
ML-4171 |
The Redis target implementation changed. Features-sets that use Redis as online targets must be recreated. View in Git. |
ML-4366 |
The MLRun images |
Deprecations#
Closed issues#
ID |
Description |
|---|---|
ML-1584 |
Can now run |
ML-2199 |
Spark operator job does not fail with default requests arguments. |
ML-2380 |
Spark runtime sustains naive user actions. |
ML-4188 |
Projects are deleted simultaneously in the backend and the UI. |
ML-4212 |
Pipeline filters that have no results now show the labels. |
ML-4214 |
Scheduled workflows with "-" in the name are no longer truncated. |
ML-4232 |
User attempts to create a consumer group with "-" now throws an error. |
ML-4316 |
Fixed: |
ML-4323 |
Fixed: pipeline step failed with "Read timed out.: get log" |
ML-4391 |
Consumer group UI now shows complete details. |
ML-4501 |
Fixed: UI shows error after deleting a function, then viewing a related job. |
ML-4533 |
UI: ML functions can now be created with upper-case letters. |
v1.4.x#
v1.4.1 (8 August 2023)#
Closed issues#
ID |
Description |
|---|---|
ML-4303 |
Archive out-of-sync leader projects. |
ML-4232 |
Consumer group names cannot include the character "-". |
v1.4.0 (23 July 2023)#
Functions#
ID |
Description |
|---|---|
ML-3474 |
New sub-package in MLRun for packing returning outputs, logging them to MLRun and unpacking inputs, parsing data items to their required type. View in Git. |
Notifications#
ID |
Description |
|---|---|
ML-21 |
Supports job notifications. See full details in Notifications, and View in Git. |
Projects#
ID |
Description |
|---|---|
ML-3375 |
Two new APIs in the MlrunProject object, used to build an image directly through project API, without creating a function and building an image for it: |
ML-4084 |
New API to run a setup script to enrich a project, when loading the project. View in Git |
Serving#
ID |
Description |
|---|---|
ML-3654 |
Updates to |
UI#
ID |
Description |
|---|---|
ML-1248 |
The engine type now displays in the Feature Set Overview tab. |
ML-2083 |
The Run on spot value now displays in the Jobs Overview tab. |
ML-3176 |
The new Passthrough button in the Create Feature Set enables creating a feature set without ingesting its data, previously supported by SDK. |
ML-3549 |
The new Resource monitoring button in the Jobs Details view opens the Grafana dashboard. |
ML-3551 |
Nested workflows ( |
ML-2922 |
The Artifacts, Datasets and Models pages have an improved filter. Enhanced look and feel in tables. |
Documentation#
ID |
Description |
|---|---|
ML-3548 |
Passing parameters between steps using the |
ML-3763 |
The relationship between GPUs and remote functions is now explained in Number of GPUs and Example of Nuclio function. |
New documentation pages#
Breaking changes#
ID |
Description |
|---|---|
ML-3733 |
|
ML-3773 |
The aggregation mechanism on Redis databases has improved, but the history of the aggregation (from before the upgrade) is lost, as if there were 0 events during that period. |
ML-4053 |
Pre-v1.4.0: When logging artifacts during a runtime (regular artifacts, not models (ModelArtifact via context.log_model) or datasets (DatasetArtifact via context.log_dataset)), they were strings in the RunObject outputs property. The strings were the target path to the file logged in the artifact. From v1.4.0, they are the store path of the artifact, and not the target path. (They now appear the same as the store paths for logging models and datasets.) This is breaking behavior only if you use the output of the run object as a parameter to another runtime and not as an input. View in Git. |
# Set 2 functions:
func1 = project.set_function(...)
func2 = project.set_function(...)
# Run the first function:
run1 = func1.run(...)
# In the function `func1` we logged a model "my_model" and an artifact "my_artifact"
run1.outputs
{
"my_model": "store://...",
"my_artifact": "store://...", # Instead of target path: "/User/.../data.csv"
}
# The function `func2` expects a `DataItem` for the logged artifact so passing it through inputs will work as `DataItem` can work with store paths:
run2 = func2.run(..., inputs={"artifact": run1.outputs["my_artifact"]})
# But passing it through a parameter won't work as the string value is now a store path and not a target path:
run2 = func2.run(..., params={"artifact": run1.outputs["my_artifact"]})
Deprecations and future deprecations#
Closed issues#
ID |
Description |
|---|---|
ML-1787 |
Optimized distribution of load between chief and workers so that heavy loads do not cause restart of kubelet. View in Git. |
ML-2773 |
Reduced memory footprint for feature vector that joins data from multiple feature sets. View in Git. |
ML-3166 |
New error message when |
ML-3420 |
Fix artifacts corruption due to overflowing size. View in Git. |
ML-3443 |
Spark ingestion engine now supports more than 2 keys in online target. Tech Preview. View in Git. |
ML-3470 |
Changes in secrets are now recorded in the audit log of the platform. View in Git. |
ML-3508 |
Improved description of list_runs. See |
ML-3621 |
|
ML-3631 |
MLRun now successfully pulls the source code from GitLab with a personal access token. View in Git. |
ML-3633 |
Fix parsing of date fields when importing a context from dict. View in Git. |
ML-3652 |
V3IO_API is now inferred from the DBPATH. View in Git. |
ML-3703 |
|
ML-3713 |
Users can now use pipeline parameters in the spec of jobs created within the workflow python file without causing run failure. View in Git. |
ML-3761 |
**kwargs now forward as expected in MLRun jobs and hyper params. View in Git. |
ML-3782 |
The (incorrect) naming of features causes error when getting the feature vector from the online feature service. The fix is an additional restriction in feature names. See Aggregations View in Git. |
ML-3806 |
Mismatch errors now printed when ingesting from Kafka into offline target. In case of errors (due to type mismatch) no errors are printed.View in Git. |
ML-3847 |
|
ML-3900 |
Improved error message when ingesting into a feature set (online target) and no features found on retrieval. View in Git. |
ML-4129 |
Errors from BigQuerySource are now forwarded to MLRun. View in Git. |
v1.3.x#
v1.3.4 (23 August 2023)#
Closed issues#
ID |
Description |
|---|---|
ML-4409 |
Importing a project.yaml now does not overwrite the artifacts with older tags. |
v1.3.3 (7 Jun 2023)#
Closed issues#
ID |
Description |
|---|---|
ML-3940 |
MLRun does not initiate log collection for runs in aborted state. View in Git. |
v1.3.2 (4 Jun 2023)#
Closed issues#
ID |
Description |
|---|---|
ML-3896 |
Fixed: MLRun API failed to get pod logs. View in Git. |
ML-3865 |
kubectl now returns logs as expected. View in Git. |
ML-3917 |
Reduced number of logs. View in Git. |
ML-3934 |
Logs are no longer collected for run pods in an unknown state. View in Git. |
v1.3.1 (18 May 2023)#
Closed issues#
ID |
Description |
|---|---|
ML-3764 |
Fixed the scikit-learn to 1.2 in the tutorial 02-model-training. (Previously pointed to 1.0.) View in Git. |
ML-3794 |
Fixed a Mask detection demo notebook (3-automatic-pipeline.ipynb). View in Git. |
ML-3819 |
Reduce overly-verbose logs on the backend side. View in Git. View in Git. |
ML-3823 |
Optimized |
Documentation#
New sections describing Git best practices and an example Nuclio function.
v1.3.0 (22 March 2023)#
Client/server matrix, prerequisites, and installing#
The MLRun server is now based on Python 3.9. It's recommended to move the client to Python 3.9 as well.
MLRun v1.3.0 maintains support for mlrun base images that are based on python 3.7. To differentiate between the images, the images based on
python 3.7 have the suffix: -py37. The correct version is automatically chosen for the built-in MLRun images according to the Python version of the MLRun client (for example, a 3.7 Jupyter gets the -py37 images).
MLRun v1.3.x maintains support for mlrun base images that are based on a python 3.7 environment. To differentiate between the images, the images based on
python 3.7 have the suffix: -py37. The correct version is automatically chosen for the built-in MLRun images according to the Python version of the MLRun client (for example, a 3.7 Jupyter gets the -py37 images).
For a Python 3.9 environment see Set up a Python 3.9 client environment.
Set up a Python 3.7 client environment (Iguazio versions up to and including v3.5.2)#
Note
There is a known bug with nbformat on the Jupyter version in Iguazio up to and including v3.5.2, which requires upgrading nbformat to 5.7.0. When using an older nbformat, some Jupyter Notebooks do not open.
To install on a Python 3.7 environment (and optionally upgrade to python 3.9 environment):
Configure the Jupyter service with the env variable
JUPYTER_PREFER_ENV_PATH=false.Within the Jupyter service, open a terminal and update conda and pip to have an up-to-date pip resolver.
$CONDA_HOME/bin/conda install -y conda=23.1.0
$CONDA_HOME/bin/conda install -y 'pip>=22.0'
$CONDA_HOME/bin/conda install -y nbformat=5.7.0
If you want to upgrade to a Python 3.9 environment, create a new conda env and activate it:
conda create -n python39 python=3.9 ipykernel -y
conda activate python39
Install mlrun:
./align_mlrun.sh
Feature store#
ID |
Description |
|---|---|
ML-2592 |
Offline data can be registered as feature sets (Tech Preview). See Create a feature set without ingesting its data. |
ML-2610 |
Supports SQLSource for batch ingestion (Tech Preview). See SQL data source. |
ML-2610 |
Supports SQLTarget for storey engine (Tech Preview). (Spark is not yet supported.) See SQL target store. |
ML-2709 |
The Spark engine now supports the steps: |
ML-2802 |
|
ML-2957 |
The username and password for the RedisNoSqlTarget are now configured using secrets, as |
ML-3008 |
Supports Spark using Redis as an online KV target, which caused a breaking change. |
ML-3373 |
Supports creating a feature vector over several feature sets with different entities. (Outer joins are Tech Preview.) See Using an offline feature vector. This API will change in a future release, moving the relationship from the feature set to the feature vector. |
Logging data#
ID |
Description |
|---|---|
ML-2845 |
Logging data using |
Projects#
ID |
Description |
|---|---|
ML-3048 |
When defining a new project from scratch, there is now a default |
Serving graphs#
ID |
Description |
|---|---|
ML-1167 |
Add support for graphs that split and merge (DAG), including a list of steps for the |
ML-2507 |
Supports configuring of consumer group name for steps following QueueSteps. See Queues and streams. |
Storey#
ID |
Description |
|---|---|
ML-2502 |
The event time in storey events is now taken from the |
UI#
ID |
Description |
|---|---|
ML-1186 |
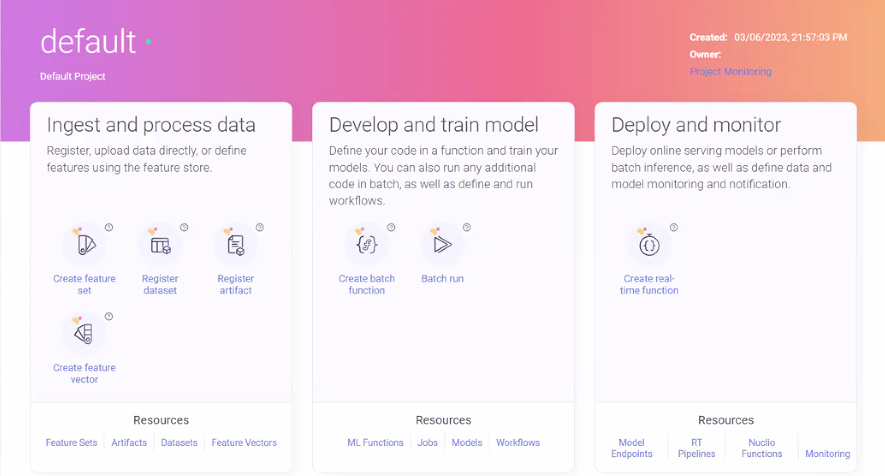
The new Projects home page provides easy and intuitive access to the full project lifecycle in three phases, with links to the relevant wizards under each phase heading: ingesting and processing data, developing and training a model, deploying and monitoring the project.
|
NA |
APIs#
ID |
Description |
|---|---|
ML-3104 |
These APIs now only return reasons in kwargs: |
ML-3204 |
New API |
Documentation#
Improvements to Set up your environment.
Infrastructure improvements#
ID |
Description |
|---|---|
ML-2609 |
MLRun server is based on Python 3.9. |
ML-2732 |
The new log collection service improves the performance and reduces heavy IO operations from the API container. The new MLRun log collector service is a gRPC server, which runs as sidecar in the mlrun-api pod (chief and worker). The service is responsible for collecting logs from run pods, writing to persisted files, and reading them on request. The new service is transparent to the end-user: there are no UI or API changes. |
Breaking changes#
The behavior of ingest with aggregation changed in v1.3.0 (storey, spark, pandas engines). Now, when you ingest a "timestamp" column, it returns
<class 'pandas._libs.tslibs.timestamps.Timestamp'>.
Previously, it returned<class 'str'>Any target data that was saved using Redis as an online target with storey engine (RedisNoSql target, introduced in 1.2.1) is not accessible after upgrading to v1.3. (Data ingested subsequent to the upgrade is unaffected.)
Deprecated and removed APIs#
Starting with v1.3.0, and continuing in subsequent releases, obsolete functions are getting removed from the code. See Deprecations and removed code.
Closed issues#
ID |
Description |
|---|---|
ML-2421 |
Artifacts logged via SDK with "/" in the name can now be viewed in the UI. View in Git. |
ML-2534 |
Jobs and Workflows pages now display the tag of the executed job (as defined in the API). View in Git. |
ML-2810 |
Fixed the Dask Worker Memory Limit Argument. View in Git. |
ML-2896 |
|
ML-3104 |
Add support for project default image. View in Git. |
ML-3119 |
Fix: MPI job run status resolution considering all workers. View in Git. |
ML-3283 |
|
ML-3286 |
Fix: Project page displayed an empty list after an upgrade View in Git. |
ML-3316 |
Users with developer and data permissions can now add members to projects they created. (Previously appeared successful in the UI but users were not added). View in Git. |
ML-3365 / 3349 |
Fix: UI Projects' metrics show N/A for all projects when ml-pipeline is down. View in Git. |
ML-3378 |
Aggregation over a fixed-window that starts at or near the epoch now functions as expected. View in Git. |
ML-3380 |
Documentation: added details on aggregation in windows. |
ML-3389 |
Hyperparameters run does not present artifacts iteration when selector is not defined. View in Git. |
ML-3424 |
Documentation: new matrix of which engines support which sources/targets. View in Git. |
ML-3505 |
Removed the upperbound on the |
ML-3575 |
|
ML-3403 |
Error on Spark ingestion with offline target without defined path (error: |
ML-3446 |
Fix: Failed MLRun Nuclio deploy needs better error messages. View in Git. |
ML-3482 |
Fixed model-monitoring incompatibility issue with mlrun client running v1.1.x and a server running v1.2.x. View in Git. |
v1.2.x#
v1.2.3 (15 May 2023)#
Closed issues#
ID |
Description |
|---|---|
ML-3287 |
UI now resets the cache upon MLRun upgrades, and the Projects page displays correctly. View in Git. |
ML-3801 |
Optimized |
ML-3819 |
Reduce overly-verbose logs on the backend side. View in Git. |
v1.2.2 (8 May 2023)#
Closed issues#
ID |
Description |
|---|---|
ML-3797, ML-3798 |
Fixed presenting and serving large-sized projects. View in Git. |
v1.2.1 (8 January 2023)#
Feature store#
Supports ingesting Avro-encoded Kafka records. View in Git.
Third party integrations#
Supports Confluent Kafka as a feature store data-source (Tech Preview). See Confluent Kafka data source.
Closed issues#
Fix: the Projects|Jobs|Monitor Workflows view is now accurate when filtering for > 1 hour. View in Git.
The Kubernetes Pods tab in Monitor Workflows now shows the complete pod details. View in Git.
Update the tooltips in Projects|Jobs|Schedule to explain that day 0 (for cron jobs) is Monday, and not Sunday. View in Git.
Fix UI crash when selecting All in the Tag dropdown list of the Projects|Feature Store|Feature Vectors tab. View in Git.
Fix: now updates
next_run_timewhen skipping scheduling due to concurrent runs. View in Git.When creating a project, the error
NotImplementedErrorwas updated to explain that MLRun does not have a DB to connect to. View in Git.When previewing a DirArtifact in the UI, it now returns the requested directory. Previously it was returning the directory list from the root of the container. View in Git.
Load source at runtime or build time now fully supports .zip files, which were not fully supported previously.
See more#
v1.2.0 (1 December 2022)#
Artifacts#
Support for artifact tagging:
SDK: Add
tag_artifactsanddelete_artifacts_tagsthat can be used to modify existing artifacts tags and have more than one version for an artifact.UI: You can add and edit artifact tags in the UI.
API: Introduce new endpoints in
/projects/<project>/tags.
Auth#
Support S3 profile and assume-role when using
fsspec.Support GitHub fine grained tokens.
Documentation#
Restructured, and added new content.
Feature store#
Support Redis as an online feature set for storey engine only. (See Redis target store.)
Fully supports ingesting with pandas engine, now equivalent to ingestion with
storeyengine (TechPreview):Support DataFrame with multi-index.
Support mlrun steps when using pandas engine:
OneHotEncoder,DateExtractor,MapValue,ImputerandFeatureValidation.
Add new step:
DropFeaturefor pandas and storey engines. (TechPreview)Add param query for
get_offline_featurefor filtering the output.
Frameworks#
Add
HuggingFaceModelServertomlrun.frameworksatmlrun.frameworks.huggingfaceto serveHuggingFacemodels.
Functions#
Add
function.with_annotations({"framework":"tensorflow"})to user-created functions.Add
overwrite_build_paramstoproject.build_function()so the user can choose whether or not to keep the build params that were used in previous function builds.deploy_functionhas a new option of mock deployment that allows running the function locally.
Installation#
New option to install
google-cloudrequirements usingmlrun[google-cloud]: when installing MLRun for integration with GCP clients, only compatible packages are installed.
Models#
The Labels in the Models > Overview tab can be edited.
Internal#
Refactor artifacts endpoints to follow the MLRun convention of
/projects/<project>/artifacts/.... (The previous API will be deprecated in a future release.)Add
/api/_internal/memory-reports/endpoints for memory related metrics to better understand the memory consumption of the API.Improve the HTTP retry mechanism.
Support a new lightweight mechanism for KFP pods to pull the run state they triggered. Default behavior is legacy, which pulls the logs of the run to figure out the run state. The new behavior can be enabled using a feature flag configured in the API.
Breaking changes#
Feature store: Ingestion using pandas now takes the dataframe and creates indices out of the entity column (and removes it as a column in this df). This could cause breakage for existing custom steps when using a pandas engine.
Closed issues#
Support logging artifacts larger than 5GB to V3IO. View in Git.
Limit KFP to kfp~=1.8.0, <1.8.14 due to non-backwards changes done in 1.8.14 for ParallelFor, which isn’t compatible with the MLRun managed KFP server (1.8.1). View in Git.
Add
artifact_pathenrichment from projectartifact_path. Previously, the parameter wasn't applied to project runs when definingproject.artifact_path. View in Git.Align timeouts for requests that are getting re-routed from worker to chief (for projects/background related endpoints). View in Git.
Fix legacy artifacts load when loading a project. Fixed corner cases when legacy artifacts were saved to yaml and loaded back into the system using
load_project(). View in Git.Fix artifact
latesttag enrichment to happen also when user defined a specific tag. View in Git.Fix zip source extraction during function build. View in Git.
Fix Docker compose deployment so Nuclio is configured properly with a platformConfig file that sets proper mounts and network configuration for Nuclio functions, meaning that they run in the same network as MLRun. View in Git.
Workaround for background tasks getting cancelled prematurely, due to the current FastAPI version that has a bug in the
starlettepackage it uses. The bug caused the task to get cancelled if the client’s HTTP connection was closed before the task was done. View in Git.Fix run fails after deploying function without defined image. View in Git.
Fix scheduled jobs failed on GKE with resource quota error. View in Git.
Can now delete a model via tag. View in Git.
See more#
v1.1.x#
v1.1.3 (28 December 2022)#
Closed issues#
The CLI supports overwriting the schedule when creating scheduling workflow. View in Git.
Slack now notifies when a project fails in
load_and_run(). View in Git.Timeout is executed properly when running a pipeline in CLI. View in Git.
Uvicorn Keep Alive Timeout (
http_connection_timeout_keep_alive) is now configurable, with default=11. This maintains API-client connections. View in Git.
See more#
v1.1.2 (20 November 2022)#
V3IO#
v3io-py bumped to 0.5.19.
v3io-fs bumped to 0.1.15.
See more#
v1.1.1 (18 October 2022)#
API#
Supports workflow scheduling.
UI#
Projects: Supports editing model labels.
See more#
v1.1.0 (6 September 2022)#
API#
MLRun scalability: Workers are used to handle the connection to the MLRun database and can be increased to improve handling of high workloads against the MLRun DB. You can configure the number of workers for an MLRun service, which is applied to the service's user-created pods. The default is 2.
v1.1.0 cannot run on top of 3.0.x.
For Iguazio versions prior to v3.5.0, the number of workers is set to 1 by default. To change this number, contact support (helm-chart change required).
Multi-instance is not supported for MLRun running on SQLite.
Supports pipeline scheduling.
Documentation#
Added Azure and S3 examples to Ingest features with Spark.
Feature store#
Supports S3, Azure, GCS targets when using Spark as an engine for the feature store.
Snowflake as datasource has a connector ID:
iguazio_platform.You can add a time-based filter condition when running
get_offline_featurewith a given vector.
Storey#
MLRun can write to parquet with flexible schema per batch for ParquetTarget: useful for inconsistent or unknown schema.
UI#
The Projects home page now has three tiles, Data, Jobs and Workflows, Deployment, that guide you through key capabilities of Iguazio, and provide quick access to common tasks.
The Projects|Jobs|Monitor Jobs tab now displays the Spark UI URL.
The information of the Drift Analysis tab is now displayed in the Model Overview.
If there is an error, the error messages are now displayed in the Projects|Jobs|Monitor jobs tab.
Workflows#
The steps in Workflows are color-coded to identify their status: blue=running; green=completed; red=error.
See more#
1.0.x#
v1.0.6 (16 August 2022)#
Closed issues#
Import from mlrun fails with "ImportError: cannot import name dataclass_transform". Workaround for previous releases: Install
pip install pydantic==1.9.2afteralign_mlrun.sh.MLRun FeatureSet was not enriching with security context when running from the UI. View in Git.
MLRun
Accesskeypresents as clear text in the mlrun yaml, when the mlrun function is created by feature set request from the UI. View in Git.
See more#
v1.0.5 (11 August 2022)#
Closed issues#
MLRun: remove root permissions. View in Git.
Users running a pipeline via CLI project run (watch=true) can now set the timeout (previously was 1 hour). View in Git.
MLRun: Supports pushing images to ECR. View in Git.
See more#
v1.0.4 (13 June 2022)#
New and updated features#
Bump storey to 1.0.6.
Add typing-extensions explicitly.
Add vulnerability check to CI and fix vulnerabilities.
Closed issues#
Limit Azure transitive dependency to avoid new bug. View in Git.
Fix GPU image to have new signing keys. View in Git.
Spark: Allow mounting v3io on driver but not executors. View in Git.
Tests: Send only string headers to align to new requests limitation. View in Git.
See more#
v1.0.3 (7 June 2022)#
New and updated features#
Jupyter Image: Relax
artifact_pathsettings and add README notebook. View in Git.Images: Fix security vulnerabilities. View in Git.
Closed issues#
API: Fix projects leader to sync enrichment to followers. View in Git.
Projects: Fixes and usability improvements for working with archives. View in Git.
See more#
v1.0.2 (19 May 2022)#
New and updated features#
Runtimes: Add java options to Spark job parameters. View in Git.
Spark: Allow setting executor and driver core parameter in Spark operator. View in Git.
API: Block unauthorized paths on files endpoints. View in Git.
Documentation: New quick start guide and updated docker install section. View in Git.
Closed issues#
Frameworks: Fix to logging the target columns in favor of model monitoring. View in Git.
Projects: Fix/support archives with project run/build/deploy methods. View in Git.
Runtimes: Fix jobs stuck in non-terminal state after node drain/pre-emption. View in Git.
Requirements: Fix ImportError on ingest to Azure. View in Git.
See more#
v1.0.0 (22 April 2022)#
New and updated features#
Feature store#
Supports snowflake as a datasource for the feature store.
Graph#
A new tab under Projects|Models named Real-time pipelines displays the real time pipeline graph, with a drill-down to view the steps and their details. [Tech Preview]
Projects#
Setting owner and members are in a dedicated Project Settings section.
The Project Monitoring report has a new tile named Consumer groups (v3io streams) that shows the total number of consumer groups, with drill-down capabilities for more details.
Resource management#
Supports preemptible nodes.
Supports configuring CPU, GPU, and memory default limits for user jobs.
UI#
Supports configuring pod priority.
Enhanced masking of sensitive data.
The dataset tab is now in the Projects main menu (was previously under the Feature store).
See more#
Open issues#
ID |
Description |
Workaround |
Opened in |
|---|---|---|---|
ML-2052 |
mlrun service default limits are not applied to the wait-container on pipeline jobs. |
NA |
v1.0.0 |
ML-2030 |
Need a way to move artifacts from test to production Spark. |
To register artifact between different environments, e.g. dev and prod, upload your artifacts to a remote storage, e.g. S3. You can change the project artifact path using MLRun or MLRun UI. |
v1.0.0 |
ML-2201 |
No error message is raised when an MPI job is created but pods cannot be scheduled. |
NA |
v1.0.0 |
ML-2407 |
Kafka ingestion service on an empty feature set returns an error. |
Ingest a sample of the data manually. This creates the schema for the feature set, and then the ingestion service accepts new records. |
v1.1.0 |
Running a workflow whose project has |
Run |
v1.1.0 |
|
ML-2489 |
Cannot pickle a class inside an mlrun function. |
Use cloudpickle instead of pickle. |
v1.2.0 |
ML-3081 |
The Monitor Workflows page does not present logs from the correct (Nuclio) deployment. |
NA |
v1.2.1 |
ML-3294 |
Dask coredump during project deletion. |
Before deleting a Dask project, verify that Dask was fully terminated. |
v1.3.0 |
ML-3315 |
Spark ingestion does not support nested aggregations. |
NA |
v1.2.1 |
ML-3341 / 2573 |
The mlrun cross-runtimes build logs should use log collector. |
NA |
v1.2.1 |
ML-3386 |
Documentation is missing full details on the feature store sources and targets. |
NA |
v1.2.1 |
ML-3445 |
|
Replace code: |
v1.3.0 |
NA |
The feature store does not support schema evolution and does not have schema enforcement. |
NA |
v1.2.1 |
ML-3526 |
Aggregation column order is not always respected (storey engine). |
NA |
v1.3.0 |
ML-3626 |
The "Save and ingest" option is disabled for a scheduled feature set. |
NA |
v1.3.0 |
ML-3627 |
The feature store should not allows ingestion of |
NA |
v1.2.1 |
ML-3636 |
|
NA |
v1.3.0 |
ML-3646 |
MapValues step on Spark ingest: keys of non-string type change to string type, sometime causing failures in graph logic. |
NA |
v1.2.1 |
ML-3744 |
|
NA |
v1.3.1 |
ML-3867 |
Cannot search for project owners by first name. |
NA |
v1.4.0 |
ML-6839 |
Schedules have a minimum interval between two scheduled jobs. By default, a job cannot be scheduled to run more than 2 times in 10 minutes. See Scheduled jobs and workflows. |
NA |
v1.6.3 |
ML-4107 |
On scheduled ingestion (storey and pandas engines) from CSV source, ingests all of the source on each schedule iteration. |
Use a different engine and/or source. |
v1.4.0 |
ML-4153 |
When creating a passthrough feature-set in the UI, with no online target, the feature-set yaml includes a parquet offline target, which is ignored. |
NA |
v1.4.0 |
ML-4166 |
Project yaml file that is very large cannot be stored. |
Do not embed the artifact object in the project yaml. |
v1.4.0 |
ML-4186 |
on |
v1.4.0 |
|
ML-4582 |
Custom packagers cannot be added to projects created in MLRun previous to v1.4.0. |
NA |
v1.5.0 |
ML-4655 |
Timestamp entities are allowed for feature store, but format is inconsistent. |
NA |
v1.5.0 |
NL-4685 |
When using columns with type "float" as feature set entities, they are saved inconsistently to key-value stores by different engines. |
Do not use columns with type float as feature set entities. |
v1.5.0 |
ML-4698 |
Parameters that are passed to a workflow are limited to 10000 chars. |
NA, external Kubeflow limitation. |
v1.5.0 |
ML-4725 |
ML functions show as if they are in the "Creating" status, although they were created and used. |
NA |
v1.4.1 |
ML-4740 |
When running function |
Prepare suitable Data-item and provide it to the batch-rerun UI. |
v1.5.0 |
ML-4769 |
After deleting a project, data is still present in the Artifacts and Executions of pipelines UI. |
NA |
v1.4.0 |
ML-4881 |
Kubeflow pipelines parallelism parameter in dsl.ParallelFor() does not work (external dependency). |
v1.4.1 |
|
ML-4942 |
The Dask dashboard requires the relevant node ports to be open. |
Your infrastructure provider must open the ports manually. If running MLRun locally or CE, make sure to port-forward the port Dask Dashboard uses to ensure it is available externally to the Kubernetes cluster. |
v1.5.0 |
ML-4956 |
A function created by SDK is initially in the "initialized" state in the UI and needs to be deployed before running it. |
In Edit, press Deploy |
v1.5.1 |
ML-5573 |
The default value of feature-set ingest() infer_options is "all" (which includes Preview) and as a result, during ingest, preview is done as well. As a result, if a validator was configured for a feature, each violation causes two messages to be printed. |
NA |
v1.6.0 |
ML-5632 |
The environmental variables of a scheduled job cannot be modified from the UI. |
||
ML-5876 |
The maximum length of project name + the longest function name for |
Keep the name combination at a maximum of 63 chars. |
v1.6.0 |
ML-7159/7704 |
The evidently app pod memory consumption grows continuously due to use of the evidently workspace and project. |
External dependency. Do not use (or only rarely use) these evidently APIs. |
v1.7.0 |
ML-7196 |
The models features statistics |
NA |
v1.7.0 |
ML-7553 |
The application API gateway is redirected even though redirection is not enabled (ssl_redirect=False). |
NA |
v1.7.0 |
ML-7568/7915 |
The SDK does not inform of invalid node selector combinations when running a function, but the pod remains stuck in the Pending state. |
v1.7.0 |
|
ML-7571 |
For executions of Dask runtimes, the UI does not show node-selectors applied to the run. |
NA |
v1.7.0 |
ML-7723 |
Spark job might remain stuck in running state upon k8s node reboot. |
NA |
v1.7.0 |
ML-7746 |
In some cases, when the pipeline is extremely large it is not displayed in the graph. |
NA |
v1.7.0 |
ML-7820 |
|
NA |
v1.7.0 |
ML-8419 |
When the MySQL server is unavailable, a project with non-V3IO model monitoring cannot be deleted. |
Run |
v1.7.1 |
ML-8427 |
Missing FK constraints in DB causes migration to fail after upgrade. |
Delete old runs before upgrading. |
v1.7.0 |
ML-8528 |
In rare circumstances, KF pipelines fail. |
Retry the workflow. |
v1.6.3 |
ML-8564 |
If the size of |
NA |
v1.8.0 |
ML-8754 |
The default spot-labels node-selector are removed when configuring the |
Use a non-default label. |
v1.7.1 |
ML-8796 |
The application runtime has two containers: the nuclio container uses the default resources and the sidecar container uses the function resources. |
NA |
v1.7.1 |
ML-8874 |
Documents that are added to different vectorstores with the same collection name cannot be differentiated. |
Avoid using same collection name over different vectorstores. |
v1.8.0 |
ML-9336 |
Attempts to delete more than 200 artifacts fail, and you are prompted to use a more granular filter. |
Configure the limit with |
v1.8.0 |
ML-9913 |
UI: There may be a discrepancy in the artifact count between the Project monitoring page and the Artifacts page when running hyper-param jobs without a best-iteration. |
Always provide a selection criteria for |
v1.8.0 |
ML-11463 |
The application graph in the model monitoring UI does not present the “dead zones” where no activity happened, and the time axis representation is not consistent. |
NA |
v1.10.0 |
ML-11654 |
MLRun serving graphs with HTTP trigger and no responder. When a serving function is configured with an HTTP trigger only and the graph does not include any |
Add a |
v1.10.0 |
ML-11468 |
A rare race-condition exists in the pagination mechanism, where concurrently issuing two paginated query requests for the same resource and with the exact same parameters (for example, asking to list functions for the same project with same filters and order type) at the exact same time may result in one of these requests receiving an MLRunConflictError response. |
Reissue the same request. |
v1.10.1 |
ML-12078 |
When Model-monitoring is enabled with V3io configured as default artifact storage, each model-endpoint creates 25 directories per day. |
Run a daily cron job to delete parquet partition directories older than a week. |
v1.11.0 |
ML-12185 |
A split graph with a collector as a merge step does not fail deployment nor invoke and produce a false response. |
Do not use the collector step as the merge step. |
v1.11.0 |
ML-12378 |
When using HTTP streaming, async does not work but works in the same manner as sync. |
NA |
v1.11.0 |
ML-12458 |
Schedules only work with UTC timezone. |
Use UTC instead of other timezones. |
V1.11.0 |
Limitations#
ID |
Description |
Workaround |
Opened in |
|---|---|---|---|
ML-1278 |
Users do not automatically have access rights to the project data of the projects they are members of. |
Assign the user access permission for the project folder. |
v0.8.0 |
ML-2014 |
Model deployment returns ResourceNotFoundException (Nuclio error that Service |
Verify that all |
v1.0.0 |
ML-3520 |
MLRun does not decompress large Kubeflow pipelines. |
NA |
v1.3.0 |
ML-3731 |
When trying to identify a failed step in a workflow with |
To see the error, use |
v1.3.0 |
ML-3743 |
Setting AWS credentials as project secret cause a build failure on EKS configured with ECR. |
When using an ECR as the external container registry, make sure that the project secrets AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY have read/write access to ECR, as described in the platform documentation |
v1.3.0 |
ML-4386 |
Notifications of local runs aren't persisted. |
NA |
v1.5.0 |
ML-4767 |
When using mlrun-gpu image, use PyTorch versions up to and including than 2.0.1, but not higher. |
You can build your own images with newer CUDA for a later release of PyTorch. |
v1.5.0 |
ML-4907 |
MLRun Client does not support Win OS. |
Use WSL instead. |
v1.3.0 |
ML-5274 |
PySpark 3.2.x cannot always read parquet files written by pyarrow 13 or above. MLRun ingest might fail when |
Call |
v1.6.0 |
ML-5669 |
When using |
You can build your own images with newer CUDA for a later release of PyTorch. |
v1.6.0 |
ML-5732 |
When using an MLRun client previous to v1.6.0, the workflow step status might show completed when it is actually aborted. |
Abort the job from the SDK instead of from the UI, or upgrade the client to v1.6.0 or higher. |
v1.6.0 |
ML-8174 |
A loaded system takes a few minutes (±5) to calculate the statistics in the Projects Monitoring pane. |
NA |
v1.7.0 |
ML-8699 |
After upgrade/restart there may be some lost notifications due to restart of the chief. |
NA |
v1.8.0 |
ML-8996 |
Occasionally, deleting projects fails with 'Fail to delete project in MLRun' |
Try deleting the project again. |
v1.8.0 |
ML-9235 |
After migrating from v1.7.x to v1.8.x, there are two artifacts with the same key that are tagged |
NA |
v1.8.0 |
ML-9929 |
Partition-by query on artifact does not sort by best-iteration. |
NA |
|
ML-9993 |
Pagination is not persistent upon browser refresh on Iguazio releases 3.6.0 and 3.6.1. |
NA |
v1.8.0 |
ML-10004 |
Batch writes to TSDB fail when the ingestion rate for the TSDB target is greater than 1/s. The result is that you cannot monitor inferencing and at some point the influencing results are dropped. |
NA |
v1.11.0 |
ML-10614 |
|
NA |
v1.11.0 |
Deprecations and removed code#
In |
ID |
Description |
|---|---|---|
v1.11.0 |
Use of underscore '_' in function names will be deprecated. Use dashes '-' instead. |
|
v1.11.0 |
TDEngine support will be removed in v1.11.0. MLRun will support TimescaleDB instead. Data will not be migrated. |
|
v1.10.0 |
SQLtargets are no longer supported. |
|
v1.10.0 |
|
|
v1.10.0 |
The Docker image |
|
v1.10.0 |
Python 3.9 is deprecated and will be removed in MLRun 1.11.0. |
|
v1.6.0 |
ML-5137 |
The Create/edit function pane was removed from the UI. |
v1.5.0 |
ML-4075 |
Python 3.7 |
v1.5.0 |
ML-4366 |
MLRun images |
v1.5.0 |
ML-3605 |
Model Monitoring: Most of the charts and KPIs in Grafana are now based on the data store target instead of the MLRun API. It is recommended to update the model monitoring dashboards since the old dashboards are not supported. |
v1.0.0 |
NA |
MLRun / Nuclio does not support python 3.6. |
Deprecated APIs#
Will be removed |
Deprecated |
API |
Use instead |
|---|---|---|---|
v1.12.0 |
v1.10.0 |
|
|
v1.12.0 |
v1.10.0 |
|
|
v1.12.0 |
v1.10.0 |
|
|
v1.12.0 |
v1.10.0 |
|
|
v1.12.0 |
v1.10.0 |
When using underscores as a name, the code no longer replaces them with dashes. |
Use dashes |
v1.12.0 |
v1.10.0 |
|
|
Removed APIs#
Version |
API |
Use instead |
|---|---|---|
v1.12.0 |
|
NA |
v1.12.0 |
|
|
v1.12.0 |
Datastore classes |
|
v1.12.0 (deprecated v1.10.0) |
|
deploy a monitored serving function or use |
v1.12.0 (deprecated v1.10.0) |
|
run a monitored serving function as a job |
v1.12.0 (deprecated v1.10.0) |
|
|
v1.12.0 (deprecated v1.10.0) |
|
Set model-monitoring credentials explicitly via |
v1.12.0 (deprecated v1.10.0) |
Monitoring old batch model endpoints via the real-time controller path (parquet windows) in |
Run job-based serving to invoke and analyze offline batch model endpoints |
v1.11.0 |
TDEngine support is removed in v1.11.0. Data is not migrated. |
MLRun supports TimescaleDB instead. |
v1.11.0 |
|
|
v1.11.0 |
|
|
v1.11.0 |
|
NA |
v1.11.0 |
|
|
v1.11.0 |
|
|
v1.11.0 |
|
|
v1.11.0 |
|
|
v1.11.0 |
|
|
v1.11.0 |
|
|
v1.11.0 |
|
|
v1.11.0 |
|
|
v1.11.0 |
|
|
v1.11.0 |
|
|
v1.11.0 |
|
|
v1.11.0 |
|
`.mounts.v3io_cred |
v1.10.0 |
Class: |
|
v1.10.0 |
|
NA |
v1.10.0 |
|
|
v1.10.0 |
|
Default value changed to |
v1.10.0 |
|
Default value changed to |
v1.10.0 |
|
Default value changed to |
v1.10.0 |
|
Default value changed to |
v1.10.0 |
|
Default value changed to |
v1.10.0 |
|
NA |
v1.10.0 |
|
NA. Make sure to save the artifact/project in the new format. |
v1.10.0 |
|
Project name differs from the name specified in the context's project YAML. This functionality is no longer supported. If you want to enable this behavior, take one of the following actions:
|
v1.10.0 |
|
|
v1.10.0 |
|
|
v1.10.0 |
|
Use datastore profiles for managing credentials |
v1.10.0 |
|
|
v1.10.0 |
|
NA |
v1.10.0 |
|
|
v1.10.0 |
|
|
v1.10.0 |
|
Set the model monitoring time window and schedule with the |
v1.10.0 |
Class: |
|
v1.10.0 |
Class: |
|
v1.10.0 |
Class: |
|
v1.10.0 |
Class: |
|
v1.10.0 |
Datastore redis: |
Use datastore profiles for managing credentials |
v1.10.0 |
Parameter: |
NA. Was not used. |
v1.10.0 |
Parameter: |
NA. Was not used. |
v1.10.0 |
Parameter: |
|
v1.10.0 |
Parameter: |
|
v1.10.0 |
Class: |
|
v1.10.0 |
Parameter: |
MLRUN_DBPATH environment variable |
v1.10.0 |
|
|
v1.8.0 |
|
NA |
v1.8.0 |
datastore |
|
v1.8.0 |
|
NA |
v1.8.0 |
Aborting runs by update request |
Abort run API |
v1.8.0 |
HTTPDB: |
NA. Was not used. |
v1.8.0 |
Feature store: |
|
v1.8.0 |
Feature store: |
|
v1.8.0 |
Feature store: |
|
v1.8.0 |
Feature store: |
|
v1.8.0 |
Artifacts: |
|
v1.8.0 |
Runtimes: |
|
v1.7.0 |
Function: |
|
v1.7.0 |
|
|
v1.7.0 |
Class: |
|
v1.7.0 |
Feature store: |
|
v1.7.0 |
|
NA. The parameter was ignored. |
v1.7.0 |
API endpoint GET: |
|
v1.7.0 |
|
|
v1.7.0 |
Parameter of mlrun.feature_store.feature_set.FeatureSet.set_targets |
|
v1.6.2 |
|
NA. The parameter was ignored. |
v1.6.0 |
|
NA. The parameter was ignored. |
v1.6.0 |
|
NA |
v1.6.0 |
Runtimes: |
|
v1.6.0 |
MLRunProject object legacy parameters |
metadata and spec |
v1.6.0 |
|
|
v1.6.0 |
|
|
v1.6.0 |
CSVSource's |
Use |
v1.6.0 |
|
|
v1.6.0 |
ttl param from pipeline |
|
v1.6.0 |
objects methods from artifacts list |
|
v1.5.0 |
user_project- and project-related parameters of |
The same parameters in project-related APIs, such as |
v1.5.0 |
|
|
v1.5.0 |
Dask |
|
v1.5.0 |
|
|
v1.5.0 |
Spark runtime |
|
v1.5.0 |
|
|
v1.5.0 |
|
|
v1.5.0 |
|
Add the function initialization to the pipeline code instead |
v1.5.0 |
The entire |
|
v1.5.0 |
|
|
v1.5.0 |
Unused artifact types: BokehArtifact, ChartArtifact |
NA |
v1.3.0 |
|
|
v1.3.0 |
|
|
v1.3.0 |
|
|
v1.3.0 |
|
NA |
v1.3.0 |
|
NA |
v1.3.0 |
|
|
v1.3.0 |
Feature-store: usage of state in graph. For example: |
|
v1.3.0 |
|
|
v1.3.0 |
|
|
v1.3.0 |
Dask |
|
v1.3.0 |
Dask |
|
Removed CLIs#
Version |
CLI |
Use instead |
|---|---|---|
v1.7.0 |
|
NA |
v1.6.0 |
deploy |
No longer supported on client side. Configure using the MLRun API. |
v1.6.0 |
project |
Not relevant. Running a schedule is now an operation. |
v1.5.0 |
|