
Projects and automation#
MLRun project is a container for all your work on a particular ML or gen AI application. Projects host functions, workflows, artifacts (datasets, models, etc.), features (sets, vectors), and configuration (parameters, secrets, source, etc.). Projects have owners and members with role-based access control.
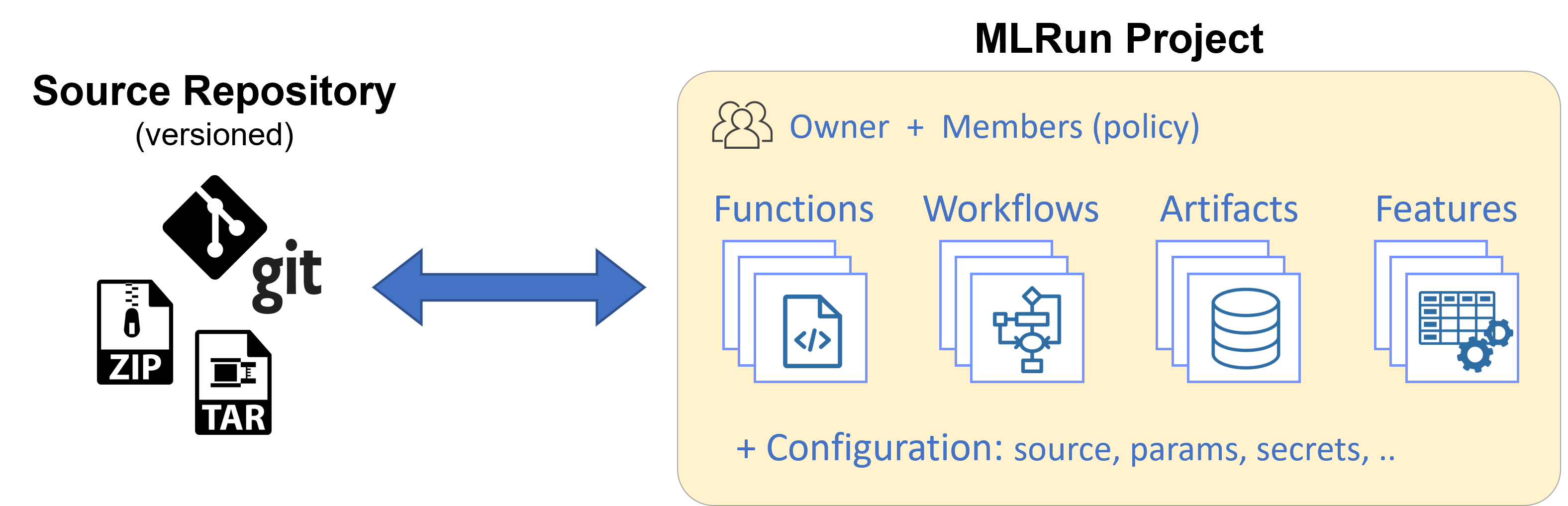
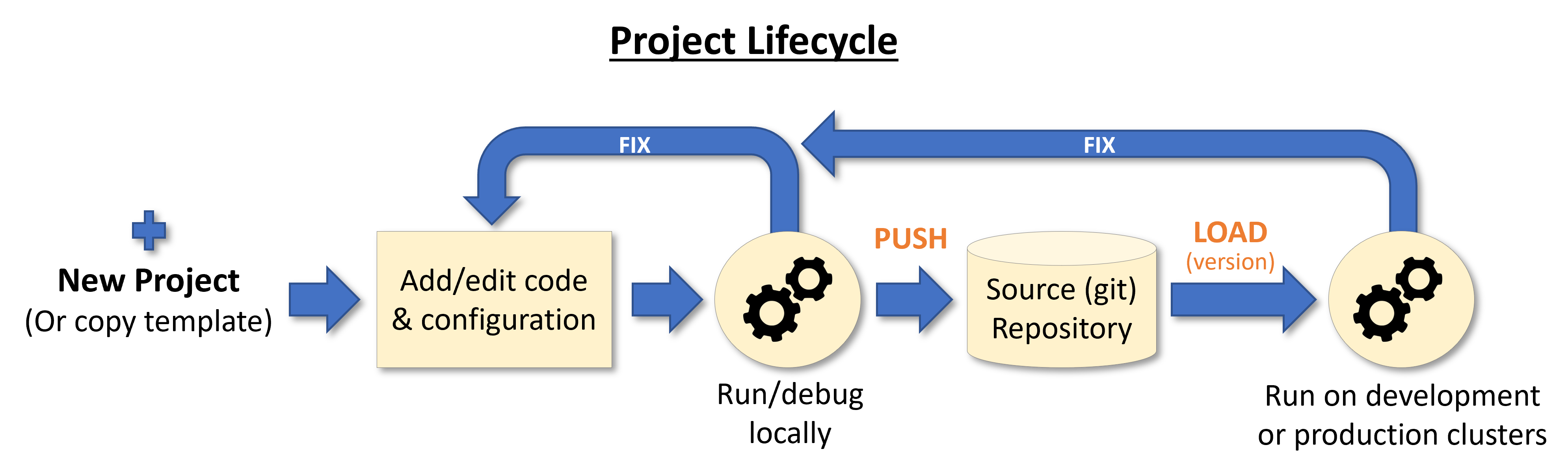
Projects are stored in a GIT or archive and map to IDE projects (in PyCharm, VSCode, etc.), which enables versioning, collaboration, and CI/CD. Projects simplify how you process data, submit jobs, run multi-stage workflows, and deploy real-time pipelines in continuous development or production environments.
In this section
See also: