
View model monitoring results in the platform UI#
This tutorial illustrates the basic model monitoring capabilities of MLRun: deploying a model to a live endpoint and observing data drift. MLRun calculates the drift using the monitoring application and stores the result in the model endpoint. The UI presents the model endpoint information and stats, including the drift status column.
In this section
Model endpoints summary list#
Select a project that has Model monitoring already enable.
From the project dashboard, press the Models tile to view the models currently deployed.
Press Model Endpoints from the menu to display a list of monitored endpoints.
The Model Endpoints summary list provides a quick view of the model monitoring data.
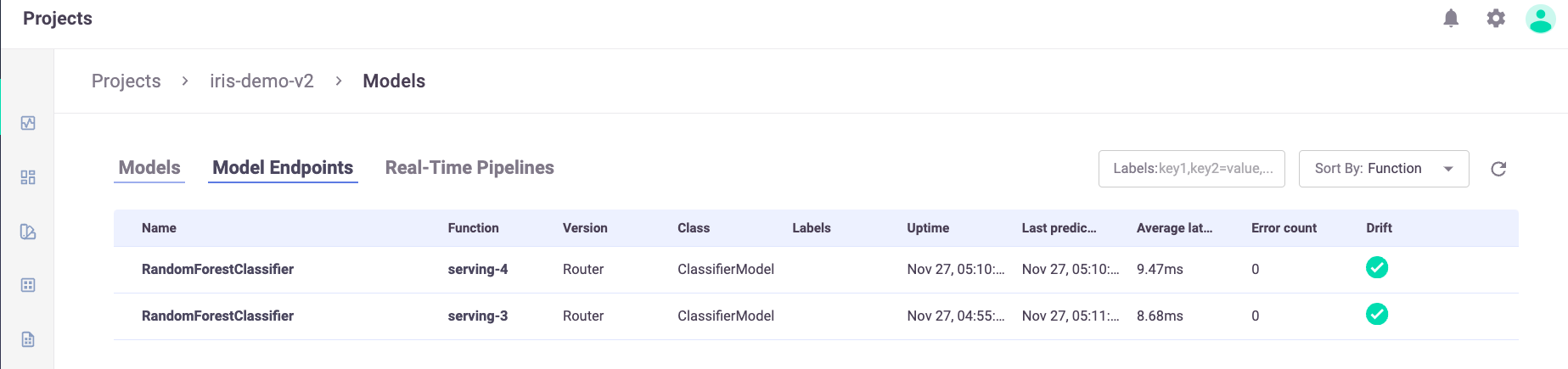
The summary page contains the following fields:
Name — the name of the model endpoint
Function — the name of the related function
Function tag — user configured tag, by default,
latestClass — the implementation class that is used by the endpoint
Labels — user configurable tags that are searchable
First prediction — first request for production data
Last prediction — most recent request for production data
Error count — includes prediction process errors such as operational issues (for example, a function in a failed state), as well as data processing errors (For example, invalid timestamps, request ids, type mismatches etc.)
Drift Status — indication of drift status (no drift (green), possible drift (yellow), drift detected (red))
Model endpoints overview#
The Model Endpoints overview pane displays general information about the selected model.
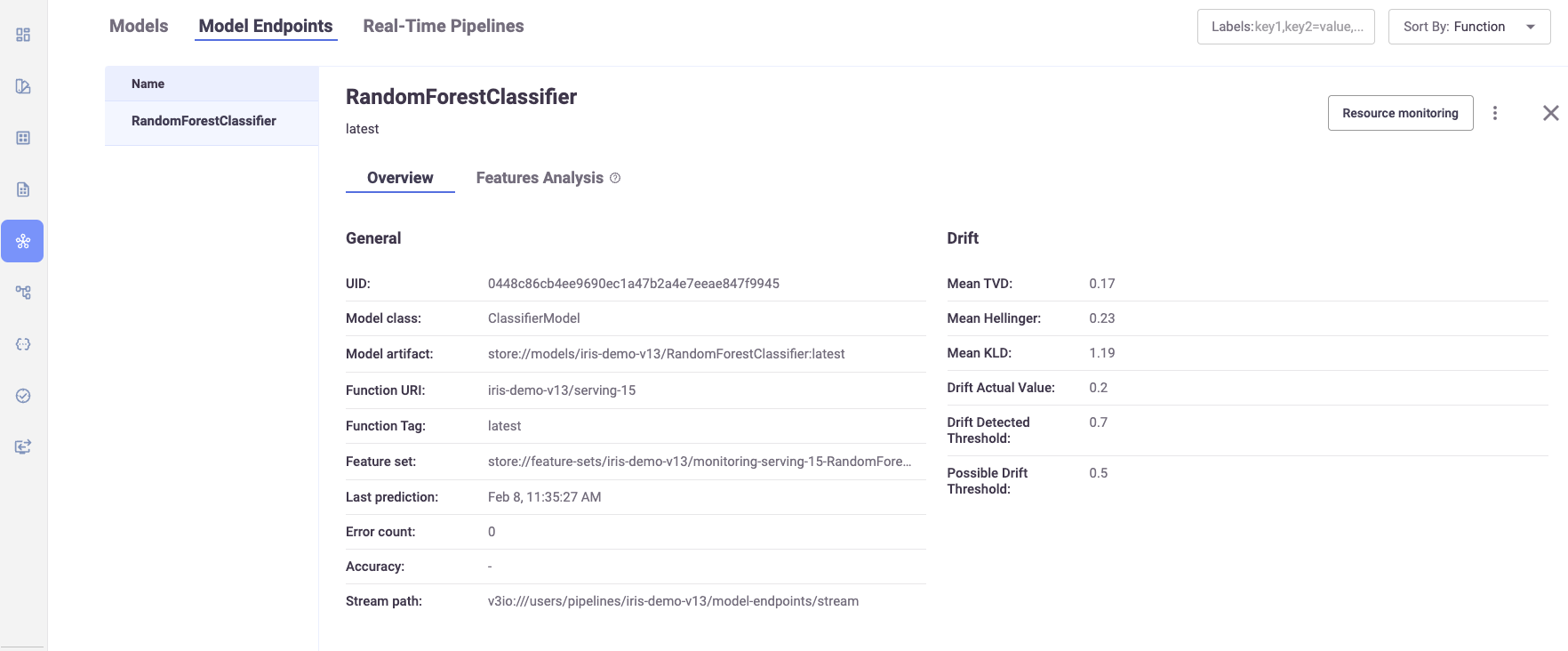
The Overview page contains the following fields:
UUID — the ID of the deployed model
Model class — the implementation class that is used by the endpoint
Model artifact — reference to the model's file location
Function URI — the MLRun function to access the model
Function Tag — the MLRun function tag
Feature set — the monitoring feature set that points to the monitoring parquet directory
Last prediction — most recent request for production data
Error count — includes prediction process errors such as operational issues (For example, a function in a failed state), as well as data processing errors (For example, invalid timestamps, request ids, type mismatches etc.)
Accuracy — a numeric value representing the accuracy of model predictions (N/A)
Stream path — the input and output stream of the selected model
Mean TVD — the mean value of the Total Variance Distance of the model features and labels
Mean Hellinger — the mean value of the Hellinger Distance of the model features and labels
Mean KLD — the mean value of the KL Divergence of the model features and labels
Drift Actual Value — the resulted drift value of the latest drift analysis calculation.
Drift Detected Threshold — pre-defined value to determine a drift
Possible Drift Threshold — pre-defined value to determine a possible drift
Note
Press Resource monitoring to get the relevant Grafana Model Monitoring Details Dashboard that displays detailed, real-time performance data of the selected model. In addition, use the ellipsis to view the YAML resource file for details about the monitored resource.
Model endpoints features analysis#
The Features Analysis pane provides details of the drift analysis in a table format with each feature and label in the selected model on its own line.
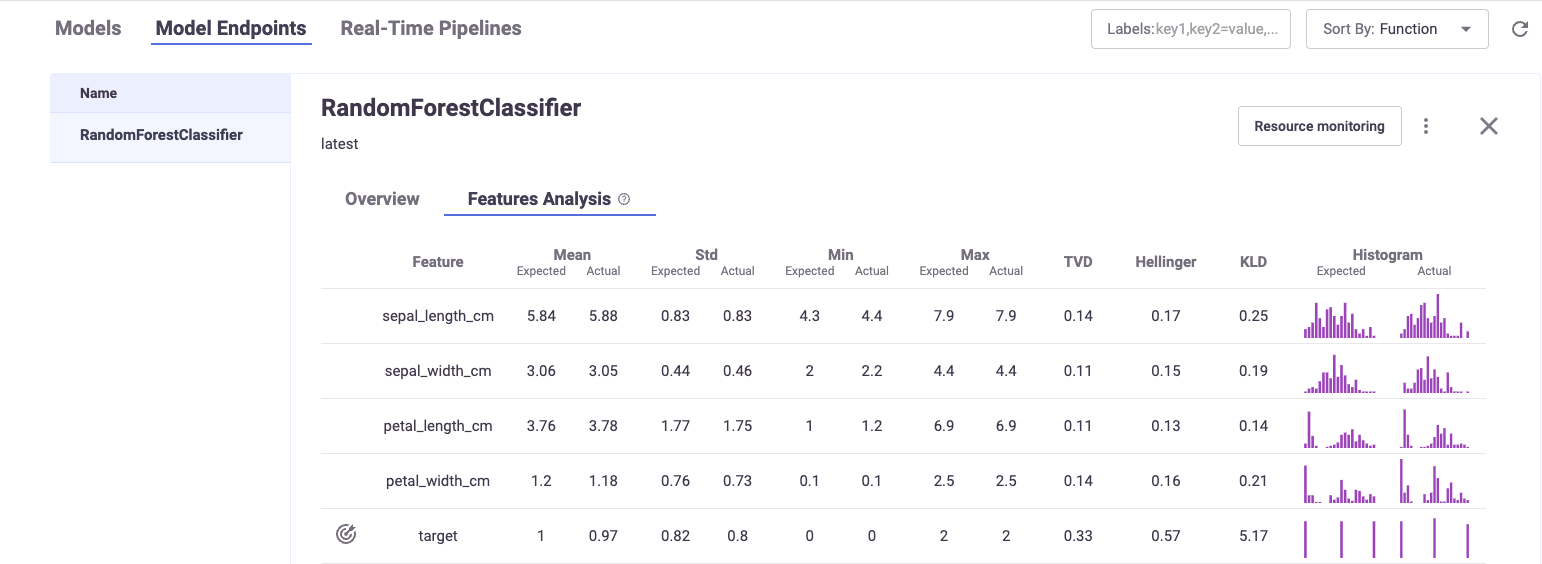
Each field has a pair of columns. The Expected column displays the results from the model training phase, and the Actual column displays the results from the live production data. The following fields are available:
Mean
STD (Standard deviation)
Min
Max
TVD
Hellinger
KLD
Histograms—the approximate representation of the distribution of the data. Hover over the bars in the graph for the details.
Model endpoints metrics#
The Metrics pane displays the pre-defined metrics for model endpoints such as predictions_per_second and latency_avg_5m. You can also define your own metrics using
mlrun.model_monitoring.applications.ModelMonitoringApplicationMetric().
Each metric can be seen by selecting its name from the drop-down list.
