
Gen AI realtime serving graph#
Learn how to create a serving graph using multiple LLM calls, including specific prompt templates, inside your complete workflow.
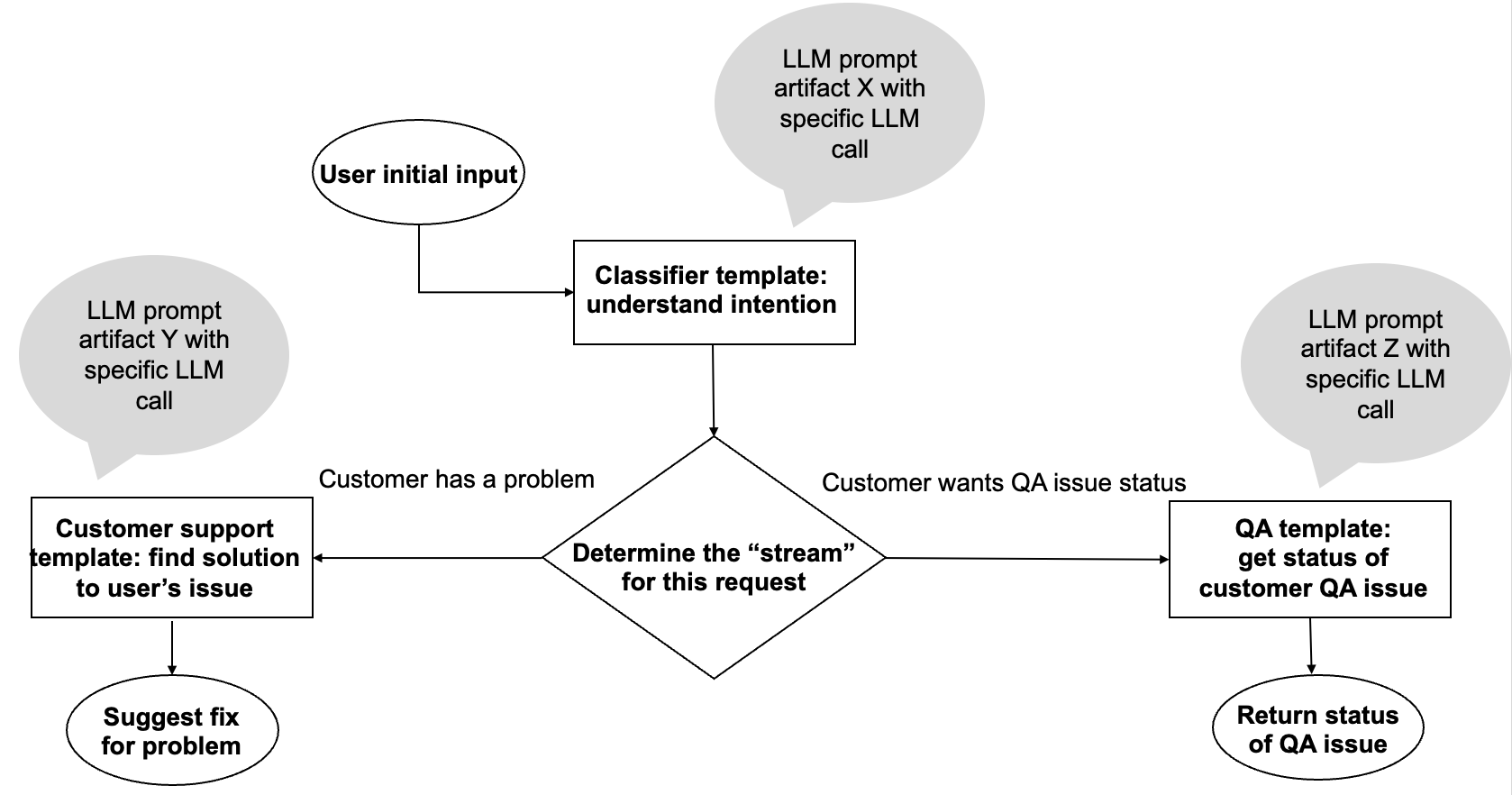
Take a project, for example, of an customer service chatbot that receives customers' requests and gives the best answer according to the customer’s specific data and the company’s procedures. This would require a few calls for LLMs, each with its purpose, potentially using different prompts and different LLMs. The first step is classification: receiving the user’s request and trying to classify it into the pre-defined flow. This step uses a specific prompt instructing the LLM to classify the request. The LLM's answer can be a short text or a number specifying the classified path. The LLM used at this stage would not require the creation of sophisticated answers, and the invocation configuration can allow only very short answers. After the relevant flows are understood, the system can ask for a description of the issue they have, or the the ticket ID, and either offer troubleshooting responses or the ticket status. In this case, the LLMs and prompts are different.
This page guides you through the basic steps to generate a serving graph using LLMs based on this flowchart. The customer support template and the QA template each have their own prompt templates and attached model.
In this section
See also
SDK#
log_llm_prompt(): Log an LLM prompt artifact to the projectlog_model(): Log a model artifact and optionally upload it to the datastoreadd_model(): Add a model and/or route to the functionModelRunnerStep: Run multiple models on each event
Guidelines#
One LLM can be used by multiple LLM prompts
The
invocation_configis specific per LLM prompt. For example, you can limit the tokens in a classification step, while other steps do not have a token limitation.When the graph is deployed, each model step, which represents a model/prompt combination, is translated to a model endpoint and can be monitored individually.
Hub steps#
You can import predefined steps from the MLRun hub and use them in your graph. Predefind steps save you time and effort. Typical usage of predefined steps includes: guardrails (toxicity check, specific subject check), classifier, translator, PDF parser. You can also save predefined steps to your private hub for reuse.
Define the LLM prompt template#
Prompt templates guide the LLM to generate responses based on user queries and the role of this specific LLM call in the workflow. They use variables to define the format of the prompt. The name of the template is important, since you will use it subsequently in filters and searches.
The prompt template format is a list[dict], using variables to define the format of the prompt:
prompt_template = [
{ "role": "system", "content": "You are a helpful assistant ..." },
{ "role": "user", "content": "please help with this issue {user_message}" }
]
There is no limitation on the list’s size, although common cases will have 2 dictionaries (system and user)
Each content can hold plain text, a place holder or a combination of both.
The place holders names are relevant for the entire template: if there is a place holder “user_input” it can be used inside a few contents, and will always be the same.
The
prompt_path/target_pathpoint to a JSON file that follows the same structure as above.(Optional) arguments: A dictionary of argument names and their description: what is the expected value.
Log the LLM prompt artifacts#
LLM prompt artifacts capture a prompt definition for LLM interactions. You can log prompt artifacts (to your project) with an inline prompt template, or from a file, and with optional metadata like generation parameters, a legend for variable injection, and references to a parent model artifact. Prompt artifacts are uniquely defined by their LLM, prompt template, and the model generation configuration.
See the parameters and examples in log_llm_prompt().
Example of logging directly with an inline prompt template
QA_prompt = project.log_llm_prompt(
"QA_prompt",
prompt_template=[
{
"role": "system",
"content": "You are a member of the QA team responsible for tracking the status of customer issues.",
},
{
"role": "user",
"content": "Provide the status of {issue_number}",
},
],
model_artifact=model_artifact,
prompt_legend={
"issue_number": {
"field": "issue_number",
"description": "The issue tracking reference in the QA system",
},
},
)
Example of logging a prompt from a file
project.log_llm_prompt(
key="qa_prompt",
prompt_path="prompts/template.json",
prompt_legend={
"question": {
"field": "user_question",
"description": "The actual question asked by the user",
}
},
model_artifact=model,
invocation_config={"temperature": 0.7, "max_tokens": 256},
description="Q&A prompt template with user-provided question",
tag="v2",
labels={"task": "qa", "stage": "experiment"},
)
Serve a graph#
This end-to-end code example implements the callflow that directs calls between customer support and QA responses illustrated above.
Models can be either local or remote (see Serving gen AI models). This example uses a remote model.
The graph uses the ModelRunnerStep, enabling the running of multiple models on each event.
When the graph is deployed, each model step, which represents a model/prompt combination, is translated to a model endpoint.
Set up environment, import the mlrun library and initialize the project:
from typing import Union
from mlrun.serving import ModelSelector
from my_modul import MsgClassifier
import mlrun
from mlrun import get_or_create_project
image = "mlrun/mlrun"
project_name = "my-project"
project = get_or_create_project(
project_name, context="./", user_project=True, allow_cross_project=True
)
class MyClassifier(ModelSelector):
def select(
self, event, available_models: list[Model]
) -> Union[list[str], list[Model]]:
return MsgClassifier.classify(event)
Define the openAI credentials and env parameters, specify and log the model, and log the llm prompts:
from mlrun.datastore.datastore_profile import OpenAIProfile
open_ai_profile = OpenAIProfile(
name="openai_profile",
api_key=os.environ.get("OPENAI_API_KEY"),
base_url=os.environ.get("OPENAI_BASE_URL"),
)
project.register_datastore_profile(open_ai_profile)
model_url = f"ds://openai_profile/gpt-4o-mini"
from src.llm_prompts import customer_support_prompt_template, qa_prompt_template
model_artifact = project.log_model(
"open-ai",
model_url=model_url,
)
classification_prompt = project.log_llm_prompt(
"classification_prompt",
prompt_template=[
{
"role": "system",
"content": "You are the first response to a customer call and need to understand whether the caller wants help with an issue or wants to get status on an open bug. In case of a bug , extract the 'issue number' from the call ",
},
{
"role": "user",
"content": "The customer inquires about {user_issue}",
},
],
model_artifact=model_artifact,
prompt_legend={
"user_issue": {
"field": "user_issue",
"description": "The original input of the user",
},
},
)
QA_prompt = project.log_llm_prompt(
"QA_prompt",
prompt_template=[
{
"role": "system",
"content": "You are a member of the QA team responsible for tracking the status of customer issues.",
},
{
"role": "user",
"content": "Provide the status of {issue_number}",
},
],
model_artifact=model_artifact,
prompt_legend={
"issue_number": {
"field": "issue_number",
"description": "The issue tracking reference in the QA system",
},
},
)
customer_support_prompt = project.log_llm_prompt(
"customer_support_prompt",
prompt_template=[
{
"role": "system",
"content": "You are a helpful customer support assistant.",
},
{
"role": "user",
"content": "Provide helpful troubleshooting information for {user_issue}",
},
],
model_artifact=model_artifact,
prompt_legend={
"user_issue": {
"field": "user_issue",
"description": "The original input of the user",
},
},
)
Add the function using the flow topology and the async engine, and add the ModelRunnerStep:
from mlrun.serving import ModelRunnerStep
from mlrun.common.schemas.model_monitoring.constants import (
ModelEndpointCreationStrategy,
)
function = project.set_function(
name="chat-bot",
kind="serving",
tag="latest",
func="./src/LLM_file.py",
image=image,
requirements=["openai==1.77.0"],
)
graph = function.set_topology("flow", engine="async")
model_runner_step = ModelRunnerStep(
name="model_runner_step",
model_runner_selector="MyClassifier", # Classify which model should be used
)
model_runner_step.add_model(
endpoint_name="qa_prompt_ep",
model_artifact=qa_prompt,
model_endpoint_creation_strategy=ModelEndpointCreationStrategy.OVERWRITE,
execution_mechanism="thread_pool",
model_class="LLModel",
)
model_runner_step.add_model(
endpoint_name="customer_support_endpoint",
model_artifact=customer_support_llm_prompt_artifact,
model_endpoint_creation_strategy=ModelEndpointCreationStrategy.OVERWRITE,
execution_mechanism="thread_pool",
model_class="LLModel",
)
graph.to(model_runner_step).respond()
Distributed pipelines#
By default, all steps of the serving graph run on the same pod. It is possible to run different steps on different pods using distributed pipelines.Typically you run steps that require CPU on one pod, and steps that require a GPU on a different pod that is running on a potentially different node that has GPU support.